
python基础大全(二)
该篇用于总结一些库的使用或工具类总和,若需要看更多工具包看该链接:推荐收藏!深度盘点上千个优秀的 Python 工具包! - 知乎 (zhihu.com)
Sqlalchemy
SQLAlchemy是一个开源的Python库,它提供了一种高级的ORM(对象关系映射)接口,可以让我们在Python代码中使用面向对象编程方式来操作数据库。
安装
pip install sqlalchemy连接Mysql
使用SQLAlchemy连接MySQL需要先安装MySQL驱动,可以使用pymysql驱动。
安装pymysql驱动:
pip install pymysql连接MySQL的示例代码如下:
from sqlalchemy import create_engine
# 连接MySQL数据库
engine = create_engine("mysql+pymysql://用户名:密码@主机/数据库名?charset=utf8")
# 测试连接
connection = engine.connect()
# 关闭连接
connection.close()其中mysql+pymysql是连接驱动,后面跟着用户名:密码@主机/数据库名?charset=utf8。
在连接字符串中,用户名和密码就是MySQL数据库的用户名和密码,主机是MySQL数据库所在的主机地址,数据库名是要连接的数据库名。
如果连接成功,会创建一个连接对象,之后可以使用这个连接对象来进行数据库的操作。
如果连接失败,会抛出异常。
Session对象
SQLAlchemy的Session对象是数据库会话的抽象。它代表了一次与数据库的交互,是用于查询和更新数据库的主要方法。Session对象的生命周期是短暂的,通常在一个请求或交互结束时关闭。
Session对象可以通过调用Session工厂方法创建:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# 创建数据库连接
engine = create_engine('mysql+pymysql://username:password@host:port/database')
Session = sessionmaker(bind=engine)
session = Session()创建了Session对象后,可以使用以下方法操作数据库:
add:将新实体类对象添加到数据库。
delete:从数据库中删除实体类对象。
query:执行数据库查询。
commit:提交对数据库的更改。
rollback:回滚对数据库的更改。
例如:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
engine = create_engine('sqlite:///example.db')
Session = sessionmaker(bind=engine)
session = Session()
# add a user
user = User(name='John Doe', age=30)
session.add(user)
session.commit()
# query users
users = session.query(User).all()
for user in users:
print(user.id, user.name, user.age)如果想关闭session,只需要调用close()即可
session.close()实体类创建规则
在SQLAlchemy中,实体类对象是用来描述数据库表的类,其中每个字段映射到数据表中的列。
以下是SQLAlchemy实体类对象的一些基本规则:
类继承:SQLAlchemy实体类必须继承自sqlalchemy.ext.declarative.declarative_base类。
列声明:每个字段都必须使用sqlalchemy.Column类声明。
列类型:每个列必须有一个数据类型,例如sqlalchemy.String或sqlalchemy.Integer。
主键:必须声明一个主键列,通常使用sqlalchemy.Column的primary_key参数。
初始值:可以使用sqlalchemy.Column的default参数指定列的默认值。
关系:可以使用sqlalchemy.orm.relationship声明两个实体类之间的关系,例如一对多或多对一关系。
这些是SQLAlchemy实体类对象的基本规则,但它们不是绝对的,你可以根据需要扩展它们。以下是一个示例,该示例定义了一个名为User的实体类,该类描述了用户数据表:
from sqlalchemy import create_engine, Column, Integer, String, Sequence
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'users' # 必须填写,对应数据表名
id = Column(Integer,primary_key=True,,autoincrement=True)
name = Column(String(50))
age = Column(Integer)
email = Column(String(120), unique=True)
engine = create_engine('sqlite:///example.db')
Base.metadata.create_all(engine)数据表操作
SQLAlchemy可以使用metadata API更新数据表的结构,这样可以方便地创建、删除数据表或更改数据表的结构。
创建数据表
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, Sequence('user_id_seq'), primary_key=True)
name = Column(String(50))
age = Column(Integer)
email = Column(String(120), unique=True)
engine = create_engine('sqlite:///example.db')
Base.metadata.create_all(engine)删除数据表
Base.metadata.drop_all(engine)更改数据表结构
from sqlalchemy import Table, MetaData, Column, Integer, String, Sequence
metadata = MetaData()
users_table = Table('users', metadata,
Column('id', Integer, Sequence('user_id_seq'), primary_key=True),
Column('name', String(50)),
Column('age', Integer),
Column('email', String(120), unique=True),
)
users_table.create(engine, checkfirst=True)数据操作
使用SQLAlchemy连接MySQL后,可以使用Session对象来操作数据库。Session对象提供了增删查改数据的方法。
增加数据
使用SQLAlchemy的session对象的add()方法来增加数据。
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# 创建数据库连接
engine = create_engine('mysql+pymysql://username:password@host:port/database')
Session = sessionmaker(bind=engine)
session = Session()
# 创建一个新的数据对象
new_data = MyTable(column1='value1', column2='value2')
# 增加新数据
session.add(new_data)
session.commit()查询数据
使用session对象的query()方法来查询数据,之后可以用.all()或者.first()返回结果,区别如下:
.all():返回包含查询后所有的数据的实体类对象列表.first():返回包含查询后第一条数据的实体类对象
可以用.filter去筛选查询的条件,例子如下
# 查询所有数据
results = session.query(MyTable).all()
# 查询第一条数据
results = session.query(MyTable).first()
# 查询特定条件的数据
results = session.query(MyTable).filter(MyTable.column1 == 'value1').all()更新数据
使用update方法更改数据,传入的参数为字典
# 更新特定条件的数据
session.query(MyTable).filter(MyTable.column1 == 'value1').update({MyTable.column2: 'new_value'})
session.commit()删除数据
使用session对象的delete()方法来删除数据
# 查询要删除的数据对象
data_to_delete = session.query(MyTable).filter(MyTable.column1 == 'value1').first()
# 删除数据
session.delete(data_to_delete)
session.commit()事务操作
事务是一组一起执行的SQL语句,它们要么全部成功,要么全部失败。使用SQLAlchemy可以通过session对象的begin()方法来开始事务,通过commit()方法来提交事务,通过rollback()方法来回滚事务。例如:
session.begin()
session.add(new_data)
session.commit()原生SQL执行
SQLAlchemy也提供了执行原生SQL的功能,使用session对象的execute()方法来执行原生SQL。例如:
result = session.execute("SELECT * FROM mytable WHERE column1 = 'value1'")SMTP
SMTP是一种提供可靠且有效的电子邮件传输的协议。SMTP是建立在FTP文件传输服务上的一种邮件服务,主要用于系统之间的邮件信息传递,并提供有关来信的通知。SMTP独立于特定的传输子系统,且只需要可靠有序的数据流信道支持,SMTP的重要特性之一是其能跨越网络传输邮件,即“SMTP邮件中继”。使用SMTP,可实现相同网络处理进程之间的邮件传输,也可通过中继器或网关实现某处理进程与其他网络之间的邮件传输。
python的smtplib提供了一种很方便的途径发送电子邮件。它对smtp协议进行了简单的封装。
安装
python3自带,无需安装
引入
import smtplib
from email.mime.text import MIMEText
from email.header import Header简单发送邮件实例
目标:发送1封邮件,无附件
定义发送内容、接受与发送地址
首先定义内容,分别为:
邮件服务器地址:
smtp.xxx.com,xxx的内容填邮箱的号,例如:163、139等发送方邮箱
发送方密码,强烈推荐授权密码,这个去相应的邮箱地址获取即可
收件方邮箱
邮件标题
邮件内容
server = 'smtp.163.com' # 发送邮件服务器地址
sender = 'xxxx@163.com' # 发送方账号
sender_password = 'xxxxxx' # 发送方密码(或授权密码)
receiver = 'xxxxx@163.com' # 收件方邮箱
title = 'Python SMTP 测试邮件' # 邮件标题
content = 'Python 测试邮件发送。。。。' # 邮件内容使用MIMEText(_text,_subtype,_charset)方法,三个参数的作用如下:
_text:文本内容_subtype:设置文本格式,默认为plain,若为html则设置文本格式为html格式_charset:设置编码,通常为utf-8
message = MIMEText(content, 'plain', 'utf-8') # 发送内容 (文本内容,发送格式,编码格式)
message['From'] = sender # 发送地址
message['To'] = receiver # 接受地址
message['Subject'] = Header(title,'utf-8') # 邮件标题开始发送
使用SMTP进行发送,步骤为:
创建SMTP对象
连接服务器
登录邮箱账号
发送邮件
关闭smtp
try:
smtp = smtplib.SMTP() # 创建SMTP对象
smtp.connect(server) # 连接服务器
smtp.login(sender, sender_password) # 登录邮箱账号
smtp.sendmail(sender, receiver, message.as_string()) # 发送账号信息
print('发送成功')
except smtplib.SMTPException:
print('邮件发送失败')
finally:
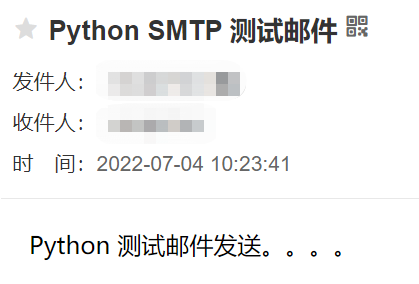
smtp.quit()检测结果
点击发送后,查看到发送成功
发送多封带有附件的邮件实例
目标:发送多封邮件,有附件,目标为不同的多个人,邮件格式为html
引入MIMEMultipart
from email.mime.multipart import MIMEMultipart定义发送内容、接受与发送地址
首先定义内容,分别为:
邮件服务器地址:
smtp.xxx.com,xxx的内容填邮箱的号,例如:163、139等发送方邮箱
发送方密码,强烈推荐授权密码,这个去相应的邮箱地址获取即可
收件方邮箱
邮件标题
邮件内容,注意用html书写
server = 'smtp.163.com' # 发送邮件服务器地址
sender = 'xxxx@163.com' # 发送方账号
sender_password = 'xxxxxx' # 发送方密码(或授权密码)
receiver = ['xxxxx@163.com','xxxxx@163.com'] # 收件方邮箱,用列表存储
title = 'Python SMTP 测试邮件' # 邮件标题
message = "<p>Python 邮件发送测试...</p> <p><a href=\"http://www.baidu.com\">这是一个链接</a></p>" # 邮件内容使用MIMEMultipart()方法,首先添加正文:
message = MIMEMultipart() # 创建一个带附件的实例
message['From'] = sender # 发送地址
message['To'] = ','.join(receiver) # 接受地址
message['Subject'] = Header(title,'utf-8') # 邮件标题
message.attach(MIMEText(content, 'html', 'utf-8')) # 添加邮件正文内容其次添加附件:
appendix = MIMEText(open('12138.txt', 'rb').read(), 'base64', 'utf-8') # 构造附件,传送当前目录下的12138.txt 文件
appendix["Content-Type"] = 'application/octet-stream' # 此处为固定的格式,可以在浏览器中查看到相关信息
appendix["Content-Disposition"] = 'attachment; filename="12138.txt"' # 这里的 filename 命名任意,即在邮件中显示的名称
message.attach(appendix) # 添加附件当然也可以增加另外一个附件,再次使用上面的方法即可。
开始发送
使用SMTP进行发送,步骤为:
创建SMTP对象
连接服务器
登录邮箱账号
发送邮件
关闭smtp
try:
smtp = smtplib.SMTP() # 创建SMTP对象
smtp.connect(server) # 连接服务器
smtp.login(sender, sender_password) # 登录邮箱账号
smtp.sendmail(sender, receiver, message.as_string()) # 发送账号信息
print('发送成功')
except smtplib.SMTPException:
print('邮件发送失败')
finally:
smtp.quit()发送嵌有图片的邮件
目标:发送多封邮件,有附件,目标为不同的多个人,邮件格式为html并嵌入图片
引入MIMEImage和MIMEMultipart
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart定义发送内容、接受与发送地址
首先定义内容,分别为:
邮件服务器地址:
smtp.xxx.com,xxx的内容填邮箱的号,例如:163、139等发送方邮箱
发送方密码,强烈推荐授权密码,这个去相应的邮箱地址获取即可
收件方邮箱
邮件标题
邮件内容,注意用html书写,
img标签中的src必须为cid:xxx
server = 'smtp.163.com' # 发送邮件服务器地址
sender = 'xxxx@163.com' # 发送方账号
sender_password = 'xxxxxx' # 发送方密码(或授权密码)
receiver = ['xxxxx@163.com','xxxxx@163.com'] # 收件方邮箱,用列表存储
title = 'Python SMTP 测试邮件' # 邮件标题
message = "<p>Python 邮件发送测试...</p> <p><a href=\"http://www.baidu.com\">这是一个链接</a><img src=\"cid:image1\" alt=\"image1\"></p>" # 邮件内容使用MIMEMultipart()方法,首先添加正文:
message = MIMEMultipart() # 创建一个带附件的实例
message['From'] = sender # 发送地址
message['To'] = ','.join(receiver) # 接受地址
message['Subject'] = Header(title,'utf-8') # 邮件标题
message.attach(MIMEText(content, 'html', 'utf-8')) # 添加邮件正文内容其次添加附件:
appendix = MIMEText(open('12138.txt', 'rb').read(), 'base64', 'utf-8') # 构造附件,传送当前目录下的12138.txt 文件
appendix["Content-Type"] = 'application/octet-stream' # 此处为固定的格式,可以在浏览器中查看到相关信息
appendix["Content-Disposition"] = 'attachment; filename="12138.txt"' # 这里的 filename 命名任意,即在邮件中显示的名称
message.attach(appendix) # 添加附件使用MIMEImage为上面的正文设置id
fp = open('img.png', 'rb')
msgImage = MIMEImage(fp.read()) # 添加图片附件
fp.close()
msgImage.add_header('Content-ID', 'image1') # 这个id用于上面html获取图片
message.attach(msgImage)开始发送
使用SMTP进行发送,步骤为:
创建SMTP对象
连接服务器
登录邮箱账号
发送邮件
关闭smtp
try:
smtp = smtplib.SMTP() # 创建SMTP对象
smtp.connect(server) # 连接服务器
smtp.login(sender, sender_password) # 登录邮箱账号
smtp.sendmail(sender, receiver, message.as_string()) # 发送账号信息
print('发送成功')
except smtplib.SMTPException:
print('邮件发送失败')
finally:
smtp.quit()subprocess
subprocess 模块是 Python 中用于执行外部命令和程序的模块,可以取代 os.system() 和 os.popen() 等函数。它提供了更加丰富和灵活的 API,可以更方便地控制外部程序的输入输出、错误处理等。
区别
subprocess 和 os 都是 Python 中用于执行外部程序的模块,它们之间有以下几个主要的区别:
API:os 提供了一些基本的系统调用函数,如 os.fork()、os.exec*() 等,可以用于创建新的进程、执行外部程序等操作;而 subprocess 则提供了更加丰富和灵活的 API,可以更方便地控制外部程序的输入输出、错误处理等。
平台兼容性:os 模块在不同平台上的实现方式可能有所不同,而 subprocess 模块则提供了跨平台的实现方式。
安全性:使用 os 模块的一些函数,如 os.system() 和 os.popen(),可能存在安全性问题,因为这些函数会将传入的参数直接作为 shell 命令执行。而 subprocess 模块提供了更加安全的 API,如 subprocess.Popen(),可以更加安全地执行外部程序。
因此,如果需要更加灵活、安全和跨平台的方式来执行外部程序,推荐使用 subprocess 模块。而如果只是需要执行一些简单的系统调用函数,可以使用 os 模块。
常用函数
以下是 subprocess 模块中常用的函数:
subprocess.run(): 运行外部命令或程序,等待其完成,并返回执行结果。
import subprocess
result = subprocess.run(['ls', '-l'], capture_output=True)
print(result.stdout)subprocess.Popen(): 启动一个新的进程来执行外部命令或程序。该函数不会阻塞当前进程,因此我们可以使用subprocess.Popen().wait()函数等待子进程结束。
案例如下:
import subprocess
process = subprocess.Popen(['ping', 'www.google.com'])
process.wait() # 等待子进程结束subprocess.call(): 运行外部命令或程序,等待其完成,并返回执行结果。
import subprocess
result = subprocess.call(['ls', '-l'])
print(result)subprocess.check_call(): 运行外部命令或程序,等待其完成,如果返回值为 0 则返回 None,否则抛出 CalledProcessError 异常。
import subprocess
try:
subprocess.check_call(['ls', 'nonexistent'])
except subprocess.CalledProcessError as e:
print('Command failed with return code', e.returncode)subprocess.check_output(): 运行外部命令或程序,等待其完成,返回执行结果。
import subprocess
result = subprocess.check_output(['ls', '-l'])
print(result)json
JSON (JavaScript 对象表示法) 是一种轻量级的数据交换格式,易于人类阅读和编写,易于机器解析和生成。它用于在Web应用程序中在客户端和服务器之间交换数据。JSON数据表示为键值对,可以嵌套。
在Python中,json 模块提供了两个主要的函数:json.dumps() 和 json.loads() 用于将 Python 对象编码为 JSON 字符串和将 JSON 字符串解码为 Python 对象。案例:
import json
# Python Dictionary
data = {
"name": "John Doe",
"age": 30,
"city": "New York"
}
# Encoding Python Dictionary to JSON
json_data = json.dumps(data)
print("JSON Encoded Data: ", json_data)
# Decoding JSON to Python Dictionary
data = json.loads(json_data)
print("Python Decoded Data: ", data)
# Python List of Dictionaries
data = [{
"name": "John Doe",
"age": 30,
"city": "New York"
},
{
"name": "Jane Doe",
"age": 28,
"city": "London"
}
]
# Encoding Python List of Dictionaries to JSON
json_data = json.dumps(data)
print("JSON Encoded Data: ", json_data)
# Decoding JSON to Python List of Dictionaries
data = json.loads(json_data)
print("Python Decoded Data: ", data)输出:
JSON Encoded Data: {"name": "John Doe", "age": 30, "city": "New York"}
Python Decoded Data: {'name': 'John Doe', 'age': 30, 'city': 'New York'}
JSON Encoded Data: [{"name": "John Doe", "age": 30, "city": "New York"}, {"name": "Jane Doe", "age": 28, "city": "London"}]
Python Decoded Data: [{'name': 'John Doe', 'age': 30, 'city': 'New York'}, {'name': 'Jane Doe', 'age': 28, 'city': 'London'}]Random
random 是 Python 的标准库之一,提供了生成随机数的功能。它提供了一系列的函数用来生成随机数、随机选择元素、打乱序列等。
引入
import randomAPI
生成一个自选范围内的随机整数
x = random.randint(1, 10)
print(x)生成一个随机浮点数
x = random.random() # 产生0到1之间的随机浮点数
y = random.uniform(1.1,5.4) # 产生1.1到5.4之间的随机浮点数,1.1和5.4可以改变成自己喜欢的部分
print(x,y)打乱一个列表
numbers = [1, 2, 3, 4, 5]
random.shuffle(numbers)
print(numbers)随机选择一个数
import string
x = random.choice([1, 2, 3, 4, 5])
y = random.choice(string.printable) # 随机字符
z = random.sample(string.printable,5) # 多个字符中生成指定数量的随机字符
print(x,y) 生成从1到100的间隔为2的随机整数
x = random.randrange(1,100,2)
print(x)生成三角形分布的随机数。三角形分布是指在给定的最小值、最大值和模式之间生成随机数,其中模式表示生成的随机数在该值附近的概率最高。
import random
# 生成一个在1和100之间且平均值为50的随机浮点数
x = random.triangular(1, 100, 50)
print(x)
# 生成5个在1和100之间且平均值为50的随机浮点数
numbers = [random.triangular(1, 100, 50) for i in range(5)]Logging
logging 是 Python 内置的日志模块,用于在程序运行时记录信息。它允许你记录程序的输出、错误信息、调试信息和其他信息,可以帮助你了解程序的运行情况。
logging 模块提供了五个级别的日志消息,分别为:
DEBUG:调试信息,用于调试程序。INFO:信息消息,用于记录程序的运行情况。WARNING:警告消息,用于记录可能会导致问题的情况。ERROR:错误消息,用于记录程序运行时出现的错误。CRITICAL:严重错误消息,用于记录程序无法继续运行的错误。
下面开始介绍Logging模块
引入
import logging输出日志
logging.debug("这里是debug信息")
logging.info("这里是信息")
logging.warning("这里是警告信息")
logging.error("这里是错误信息")
logging.critical("这里是严重错误信息")handler配置
logging 模块支持将日志消息写入文件、输出到控制台、发送到网络等功能。你可以根据你的需求来配置日志消息的输出方式。只需要用到handler模块即可。下面是一个简单的例子,用于将日志消息写入文件:
import logging
# 设置日志记录器
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# 创建文件处理器并设置日志级别
handler = logging.FileHandler('log.txt')
handler.setLevel(logging.INFO)
# 创建日志格式器
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 将格式器添加到文件处理器
handler.setFormatter(formatter)
# 将文件处理器添加到日志记录器
logger.addHandler(handler)
# 记录日志消息
logger.info('This is an info message')datetime
datetime 是 Python 内置的日期和时间处理模块。它提供了许多函数和类来处理日期和时间,包括:
datetime.datetime类:表示日期和时间的类。datetime.timedelta类:表示时间的间隔的类。datetime.time类:表示时间的类。datetime.date类:表示日期的类。
你可以使用 datetime 模块中的函数和类来处理日期和时间,还可以使用 datetime 模块中的其他函数和类来处理日期和时间。例如,你可以使用 datetime.timedelta 类来表示时间的间隔,并使用 datetime.datetime 类的加法运算符来加上或减去时间的间隔,从而计算出某个日期或时间的前后时间。
datetime
datetime类是Python中处理日期和时间的常用类,它提供了很多方法和函数用于对日期和时间进行处理。使用如下方式引入:
from datetime import datetime首先认识%Y-%m-%d %H:%M:%S,这是一个日期时间格式字符串,表示年份-月份-日期 小时:分钟:秒。其中,%Y表示四位数年份,%m表示月份(01-12),%d表示日期(01-31),%H表示小时(00-23),%M表示分钟(00-59),%S表示秒数(00-59)。这种日期时间格式字符串通常用于计算机程序中对日期时间的格式化和处理。例如,2023年2月21日下午3点30分30秒可以表示为"2023-02-21 15:30:30"。
常用日期时间格式字符串内涵如下:
%Y:年%m:月,范围01-12%d:日,范围01-31%w:周,范围0-6,其中0表示周日%H:时,范围00-23%M:分,范围00-59%S:秒,范围00-59%f:微秒
以下是一些常用的方法和函数以及它们的使用示例:
today() - 返回当前日期
from datetime import datetime
today = datetime.today()
print(today) # 输出当前日期和时间,例如:2023-02-22 15:30:30.123456now() - 返回当前日期和时间
from datetime import datetime
now = datetime.now()
print(now) # 输出当前日期和时间,例如:2023-02-22 15:30:30.123456strftime() - 将datetime对象格式化为字符串
from datetime import datetime
dt = datetime.now()
str_date = dt.strftime("%Y-%m-%d %H:%M:%S")
print(str_date) # 输出格式化后的日期和时间,例如:2023-02-22 15:30:30strptime() - 将字符串解析为datetime对象
from datetime import datetime
date_str = "2023-02-22 15:30:30"
dt = datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
print(dt) # 输出解析后的datetime对象,例如:2023-02-22 15:30:30replace() - 替换datetime对象中的某些属性值
from datetime import datetime, timedelta
dt = datetime.now()
dt = dt.replace(hour=12, minute=0, second=0, microsecond=0)
print(dt) # 输出替换后的datetime对象,例如:2023-02-22 12:00:00timedelta
timedelta类是Python中表示时间间隔的类,它可以用于对日期和时间进行加减运算。
使用如下方式引入:
from datetime import timedelta以下是一些常用的方法和函数以及它们的使用示例:
days, seconds, microseconds - 访问时间间隔中的天数、秒数和微秒数属性
from datetime import timedelta
td = timedelta(days=1, seconds=3600, microseconds=1000)
print(td.days) # 输出1
print(td.seconds) # 输出3600
print(td.microseconds) # 输出1000total_seconds() - 返回时间间隔的总秒数
from datetime import timedelta
td = timedelta(days=1, seconds=3600, microseconds=1000)
total_seconds = td.total_seconds()
print(total_seconds) # 输出86400.001add()和sub() - 两个时间间隔对象相加或相减
from datetime import timedelta
td1 = timedelta(days=1, seconds=3600, microseconds=1000)
td2 = timedelta(days=2, seconds=7200, microseconds=2000)
td_sum = td1 + td2
td_diff = td2 - td1
print(td_sum) # 输出3 days, 2:00:02
print(td_diff) # 输出1 day, 1:59:58mul()和truediv() - 时间间隔对象的乘法和除法运算
from datetime import timedelta
td = timedelta(days=1, seconds=3600, microseconds=1000)
td_mul = td * 2
td_div = td / 2
print(td_mul) # 输出2 days, 2:00:02
print(td_div) # 输出0:12:00.000500seconds - 将时间间隔转换为秒数
from datetime import timedelta
td = timedelta(days=1, seconds=3600, microseconds=1000)
seconds = td.seconds
print(seconds) # 输出3600Zipfile
zipfile模块用来做zip格式编码的压缩和解压缩。
zipfile里有两个非常重要的class, 分别是ZipFile和ZipInfo, 在绝大多数的情况下,我们只需要使用这两个class就可以了。ZipFile是主要的类,用来创建和读取zip文件而ZipInfo是存储的zip文件的每个文件的信息的。
引入
import zipfile读取压缩文件
可以使用 zipfile 模块中的 ZipFile 类来读取压缩文件。下面是一个示例,它打开名为 myfiles.zip 的压缩文件并读取文件列表:
import zipfile
with zipfile.ZipFile("myfiles.zip", 'r') as zip_ref:
for file in zip_ref.namelist():
print(file)如果需要读取压缩文件中的具体文件,可以使用 ZipFile.open() 或 ZipFile.read()方法来读取文件内容。
with zipfile.ZipFile("myfiles.zip", 'r') as zip_ref:
with zip_ref.open("file1.txt") as file:
print(file.read())或者
with zipfile.ZipFile("myfiles.zip", 'r') as zip_ref:
data = zip_ref.read("file1.txt")
print(data)压缩文件
若要压缩文件,使用ZipFile 对象,并用compression指定压缩模式
class zipfile.ZipFile(file, mode='r', compression=ZIP_STORED, allowZip64=True, compresslevel=None, *, strict_timestamps=True)filename为原文件名,arcname为存档文件名,compress_type指定压缩模式
ZipFile.write(filename, arcname=None, compress_type=None, compresslevel=None)压缩模式 | 含义 |
|---|---|
ZIP_STORED | 不压缩,默认值 |
ZIP_DEFLATED | 常用的 ZIP 压缩 |
ZIP_BZIP2 | BZIP2 压缩 |
ZIP_LZMA | LZMA 压缩 |
import zipfile
# 使用with写入压缩文件
with zipfile.ZipFile("testzip.zip", "w", compression=zipfile.ZIP_DEFLATED) as zf:
zf.write("TestToExcel.xlsx") # 写入压缩文件
zf.write("TestToExcel02.xlsx", "testZIP/TestToExcel02.xlsx") # 写入压缩文件,并指定压缩后该文件在压缩文件中的位置如果需要在压缩文件中添加新文件或删除文件,需要使用 zipfile.PyZipFile 类:
from zipfile import PyZipFile
with PyZipFile("test.zip", mode='w') as zf:
zf.writepy("mymodule")
zf.write("README.txt")
zf.writestr("info.txt", "this archive contains mymodule and README.txt")对于要压缩一整个文件夹,zipfile就没有那么方便了,这里可以使用 shutil 模块中的 make_archive() 函数来压缩整个文件夹和文件夹中的所有文件。
下面是一个示例,它将文件夹 myfolder 和其中的所有文件打包到名为 myfolder.zip 的压缩文件中:
import shutil
shutil.make_archive('myfolder', 'zip', 'myfolder')解压文件
可以使用 zip.extractall() 或 zip.extract() 方法解压文件
with zipfile.ZipFile("testzip.zip", "r") as zf:
zf.extractall("testzip") # 解压全部内容,并且指定解压的具体位置
zf.extract("file1.txt", "testzip") # 解压压缩文件中的某个文件,并且指定解压的具体位置需要注意如果指定的目录不存在,需要先创建目录。
或者可以用使用 shutil 模块中的 unpack_archive() 函数来解压文件。下面是一个示例,它将文件 myfiles.zip 解压到名为 extracted_files 的文件夹中:
import shutil
shutil.unpack_archive("myfiles.zip", "extracted_files")PyInstaller
完成一个python项目以后,可以使用 PyInstaller将Python程序生成可直接运行的程序,这个程序就可以被分发到对应的 Windows 或 Mac OS X 平台上,并且不需要部署python环境下运行程序。
安装
pip install pyinstaller命令
创建一个main.py,使用命令行工具进入到此python文件目录下,执行如下命令:
pyinstaller -D main.py完毕后将dist目录下的程序提取出来即可,PyInstaller支持如下表所示的常用选项。
指令 | 行为 |
|---|---|
-h,--help | 查看该模块的帮助信息 |
-F,-onefile | 产生单个的可执行文件 |
-D,--onedir | 产生一个目录(包含多个文件)作为可执行程序 |
-a,--ascii | 不包含 Unicode 字符集支持 |
-d,--debug | 产生 debug 版本的可执行文件 |
-w,--windowed,--noconsolc | 指定程序运行时不显示命令行窗口(仅对 Windows 有效) |
-c,--nowindowed,--console | 指定使用命令行窗口运行程序(仅对 Windows 有效) |
-o DIR,--out=DIR | 指定 spec 文件的生成目录。如果没有指定,则默认使用当前目录来生成 spec 文件 |
-p DIR,--path=DIR | 设置 Python 导入模块的路径(和设置 PYTHONPATH 环境变量的作用相似)。也可使用路径分隔符(Windows 使用分号,Linux 使用冒号)来分隔多个路径 |
-n NAME,--name=NAME | 指定项目(产生的 spec)名字。如果省略该选项,那么第一个脚本的主文件名将作为 spec 的名字 |