
深入浅出 Hugging Face:解锁 NLP 的强大工具
Hugging Face 是一个专注于自然语言处理(NLP)和人工智能(AI)的开源社区和平台,它提供了多种工具和服务,涵盖了从模型开发到部署的整个流程,帮助开发者、研究人员和企业快速构建和部署 AI 模型。Hugging Face 以其开源的 Transformers 库闻名,同时也提供了模型托管、数据集共享、应用部署等一站式服务。
以下是其相关网址
Hugging Face官方网址:Hugging Face – The AI community building the future.
Hugging Face 官方v4.49.0版本中文文档:🤗 Transformers简介
安装
pytorch安装
为了能够正常使用Hugging Face的核心产品,我们需要首先安装pytorch。这是因为Hugging Face对pytorch支持非常友好,并且pytorch也是非常热门的一个深度学习框架。
这是pytorch相关链接:
pytorch官网: https://pytorch.org/
pytorch安装地址: https://pytorch.org/get-started/locally/
pytorch官方蚂蚁蜜蜂分类数据集下载地址:https://download.pytorch.org/tutorial/hymenoptera_data.zip
首先查看电脑上的cuda版本,使用如下命令查看:
nvidia-smi运行后,可在CUDA VERSION查看cuda版本,NVIDIA-SMI为当前显卡驱动的版本号。
进入pytorch安装地址,找到对应的CUDA版本进行pip的安装,假设CUDA的版本为11.7,那么根据官网可以执行如下命令安装pytorch:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117若没有显卡(集显),可以使用CPU版本安装pytorch:
pip install torch torchvision torchaudio安装Hugging Face的核心产品
使用如下命令安装:
pip install transformers datasets安装依赖的第三方库
pip install accelerate模型默认下载位置
通过Hugging Face的Transformers库自动下载模型,会先缓存在默认路径:
Linux:~/.cache/huggingface/hub
Windows :C:\Users\<你的用户名>\.cache\huggingface\hub
缓存的模型文件以哈希值形式储存
进入其中一个模型缓存文件夹(以models--bert-base-uncased为例子)
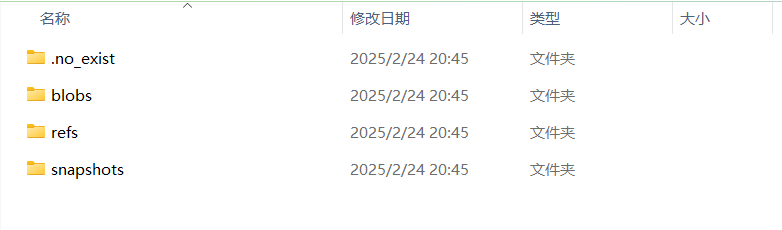
文件的作用如下(引自:https://blog.csdn.net/yyh2508298730/article/details/137773125):
refs:是一个指针文件,使用Hugging Face的模型或数据集时,系统会通过检查refs文件夹中的信息,确定是否需要更新本地缓存的文件。
blobs:文件夹包含已下载的实际文件。每个文件的名称就是它们的哈希值。
snapshots:文件夹包含指向上述 blob 的符号链接。它本身由多个文件夹组成:每个已知版本一个!该文件夹中不具有实体属性,是连接到blobs中哈希值文件的连接。通过这种方式创建的框架,实现了文件共享的机制。如果在修订版本bbbbbb中获取的同一个文件具有相同的哈希值,那么该文件就不需要被重新下载。这意味着,即使在不同的修订版本中,只要文件内容没有变化,就可以复用之前下载的文件,避免了不必要的重复下载。
Pipeline
Hugging Face 的 Pipeline 是一个高级 API,旨在简化自然语言处理(NLP)任务的执行。它封装了模型的加载、预处理、推理和后处理等步骤(Pipeline 主要用于推理(inference),而不是训练模型),使用户能够轻松完成各种 NLP 任务。
官方文档:Pipelines
使用pipline非常简单,以情绪分析为例子(注意网络环境,它会自动下载对应的模型然后使用):
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("The service attitude of this store is very good!")
print(result)输出:
No model was supplied, defaulted to distilbert/distilbert-base-uncased-finetuned-sst-2-english and revision 714eb0f (https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
Device set to use cuda:0
[{'label': 'POSITIVE', 'score': 0.9998334646224976}]它会自动选择模型,并提示所使用的设备
任务类型
Pipeline 支持各种各样的任务类型,以下是一些常见的任务类型:
sentiment-analysis: 文本分类(Text Classification)
text-generation: 文本生成(Text Generation)
ner: 命名实体识别(Named Entity Recognition, NER)
question-answering: 问答系统(Question Answering)
translation_xx_to_yy: 翻译(Translation)
summarization: 文本摘要(Summarization)
fill-mask: 填空(Fill-Mask)
zero-shot-classification: 零样本分类(Zero-Shot Classification)
conversational: 对话系统(Conversational)
feature-extraction: 特征提取(Feature Extraction)
text-similarity: 文本相似度(Text Similarity)
text-to-speech: 文本转语音(Text-to-Speech)
automatic-speech-recognition: 语音识别(Automatic Speech Recognition, ASR)
image-classification: 图像分类(Image Classification)
image-segmentation: 图像分割(Image Segmentation)
object-detection: 目标检测(Object Detection)
video-classification: 视频分类(Video Classification)
text-to-image: 文本到图像生成(Text-to-Image Generation)
text-to-video: 文本到视频生成(Text-to-Video Generation)
text-to-audio: 文本到音频生成(Text-to-Audio Generation)
Pipeline切换任务类型非常简单,这里我做几个例子:
文本生成:
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
result = generator("Once upon a time", max_length=50, num_return_sequences=2)
print(result)对话系统:
from transformers import pipeline
chatbot = pipeline("conversational", model="microsoft/DialoGPT-medium")
conversation = chatbot("Hi, how are you?")
print(conversation)翻译:
from transformers import pipeline
translator = pipeline("translation_en_to_fr", model="Helsinki-NLP/opus-mt-en-fr")
result = translator("Hello, how are you?", max_length=40)
print(result)有些模型需要提供特点的模型,当调用某一个task时,会返回对应的对象,这些对象的参数都可以在官方文档上查看,这里不再赘述
指定模型
pipelines可以指定特定的模型,可以指定线下线上的模型。在任务类型这一节中,我演示了如何加载线上模型,以下演示如何加载线上模型:
from transformers import pipeline
# 加载本地模型
generator = pipeline("text-generation", model="./path/to/local/model")
result = generator("Once upon a time", max_length=50)
print(result)不仅如此,分词器也可以指定线下的:
from transformers import pipeline
# 加载本地模型和分词器
generator = pipeline("text-generation", model="./path/to/local/model", tokenizer="./path/to/local/tokenizer")
result = generator("Once upon a time", max_length=50)
print(result)也可以线下线上结合使用:
from transformers import pipeline
# 加载本地模型,但使用 Hugging Face Hub 上的分词器
generator = pipeline("text-generation", model="./path/to/local/model", tokenizer="gpt2")
result = generator("Once upon a time", max_length=50)
print(result)Datasets
Hugging Face 的 Datasets 库是一个高效、灵活的工具,专门用于加载、处理和共享自然语言处理(NLP)以及其他机器学习任务中的数据集。它可以简化数据集的加载和预处理流程,同时提供高性能的数据处理能力。
加载数据集
Hugging Face Hub 提供了大量公开数据集,可以直接通过名称加载。(公开数据集网址:Hugging Face – The AI community building the future.):
from datasets import load_dataset
# 加载 IMDb 电影评论数据集
dataset = load_dataset("imdb")
print(dataset)输出结果:
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
})注意下载时的网络环境。
有些数据集包含多个子集(如训练集、测试集、验证集),可以通过 split 参数加载特定子集:
# 只加载训练集
train_dataset = load_dataset("imdb", split="train")
print(train_dataset)加载时可以直接拆分训练集和测试集
dataset = load_dataset('glue', 'mrpc', split=['train', 'test'])Datasets 库支持从本地文件加载数据集,支持多种格式(如 CSV、JSON、文本文件等)
加载 CSV 文件
dataset = load_dataset("csv", data_files="path/to/file.csv")加载 JSON 文件
dataset = load_dataset("json", data_files="path/to/file.json")加载文本文件
dataset = load_dataset("text", data_files="path/to/file.txt")加载多个文件
dataset = load_dataset("csv", data_files={"train": "train.csv", "test": "test.csv"})访问数据
查看特征(列名)
print(dataset['train'].features)按索引访问
可以通过索引访问数据集中的某一行
dataset['train'][0]按列访问
可以通过列名访问某一列的所有数据
dataset['train']['sentence']数据集操作
过滤数据
# 过滤出 label 为 1 的数据
filtered_dataset = dataset['train'].filter(lambda example: example['label'] == 1)
def filter_func(example):
example['label'] == 1
filtered_dataset = dataset['train'].filter(filter_func)排序数据
# 根据 sentence 的长度排序
sorted_dataset = dataset['train'].sort('sentence')
sorted_dataset = dataset['train'].sort('sentence', key=lambda x: len(x))分片数据
# 选择前 5 条数据
sliced_dataset = dataset['train'].select([0, 1, 2, 3, 4])
# 选择前 100 条数据
sliced_dataset = dataset['train'].select(range(100))拆分数据集与训练集
# 将训练集拆分为训练集和测试集
split_dataset = dataset['train'].train_test_split(test_size=0.2) # 20% 作为测试集数据映射
此方法可以对数据集中的每个样本进行自定义处理,例子如下:
def preprocess_function(example):
example['sentence'] = example['sentence'].lower()
return example
train_dataset = dataset['train'].map(preprocess_function)map支持多批量操作:
train_dataset = dataset['train'].map(preprocess_function, batched=True, batch_size=1000)这样就可以在处理时进行批量处理从而减少处理的时间
保存数据集
将处理后的数据集保存到磁盘:
dataset.save_to_disk("path/to/save")从磁盘加载已保存的数据集:
from datasets import load_from_disk
dataset = load_from_disk("path/to/save")Tokenizer
在Hugging Face的Transformers库中,Tokenizer(分词器)用于将原始文本转换为模型可以理解的数字形式(通常是整数ID)。Tokenizer的主要负责分词和词汇编码,并大幅度简化该流程。
加载 Tokenizer
from transformers import AutoTokenizer
# 加载预训练的分词器(例如 BERT 的分词器)
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")AutoTokenizer是一个通用类,可以根据模型名称自动选择合适的分词器。
预处理
Tokenizer支持对输入文本进行完整的预处理,包括分词、添加特殊标记、转换为 ID、填充或截断等
text = "Hello, how are you?"
tokens = tokenizer(text)
print(tokens)输出:
{
'input_ids': [101, 7592, 1010, 2129, 2024, 2017, 1029, 102],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0] # 仅在处理句子对时出现
}改键值对含义如下:
input_ids:token 对应的 ID 列表。attention_mask:注意力掩码,指示哪些 token 是实际内容(1),哪些是填充内容(0)。token_type_ids(可选):用于区分句子对的任务(如 BERT)。
在预处理中也包含以下流程:
包含特殊标记:会自动添加模型所需的特殊标记(如
[CLS]、[SEP]等)。转换为 ID:将 token 映射为词汇表中的 ID。
这里可以将分词后的结果自动转成张量,只需要设置return_tensors参数即可
text = "Hello, how are you?"
tokens = tokenizer(text, return_tensors="pt")
print(tokens)输出:
{
'input_ids': tensor([[ 101, 7592, 1010, 2129, 2024, 2017, 1029, 102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])
}指定不同的return_tensors参数,可以返回不同深度学习框架的张量。return_tensors 参数支持的选项包括:
"pt":PyTorch 张量"tf":TensorFlow 张量"np":NumPy 数组"jax":JAX 张量None:Python 列表(默认值)
批量预处理
Tokenizer 支持批量处理输入文本,并自动处理填充和截断。
texts = ["Hello, how are you?", "I'm fine, thank you!"]
# 编码批量文本
encoded_inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
print(encoded_inputs)输出:
{
'input_ids': tensor([[ 101, 7592, 1010, 2129, 2024, 2017, 1029, 102],
[ 101, 1045, 1005, 2310, 2986, 1010, 5256, 2017, 999, 102]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
}padding=True:自动填充到最长序列的长度。truncation=True:自动截断超过模型最大长度的文本。return_tensors="pt":返回 PyTorch 张量(可选"tf"返回 TensorFlow 张量)。
填充和截断
Tokenizer可以自动处理输入序列的填充和截断。
通过设置参数max_length,当输入的句子小于这个数字时,会自动填充。例如:
encoded_input = tokenizer(text, padding="max_length", max_length=10)
print(encoded_input)输出:
{
'input_ids': [101, 7592, 1010, 2129, 2024, 2017, 1029, 102, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]
}当输入的句子大于这个数字时,会自动截断。例如:
encoded_input = tokenizer(text, truncation=True, max_length=5)
print(encoded_input)输出:
{
'input_ids': [101, 7592, 1010, 2129, 102],
'attention_mask': [1, 1, 1, 1, 1]
}注意:在填充和截断时会将特殊标记算在定义的长度里面。
分词
text = "Hello, how are you?"
tokens = tokenizer.tokenize(text)
print(tokens)输出
['hello', ',', 'how', 'are', 'you', '?']转换为 Token IDs
将 token 映射为模型词汇表中的整数 ID。
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(token_ids)输出:
[7592, 1010, 2129, 2024, 2017, 1029]编码文本(Encode Text)
直接将文本转换为 token IDs,同时添加特殊标记(如[CLS]和[SEP])
encoded_input = tokenizer.encode(text)
print(encoded_input)输出:
[101, 7592, 1010, 2129, 2024, 2017, 1029, 102]101 是 [CLS] 的 ID,102 是 [SEP] 的 ID。
当然,可以选择不自动添加特殊标记:
encoded_input = tokenizer.encode(text, add_special_tokens=True) # 默认添加特殊标记
encoded_input = tokenizer.encode(text, add_special_tokens=False) # 不添加特殊标记解码文本(Decode Text)
将 token IDs 转换回文本
decoded_text = tokenizer.decode(encoded_input)
print(decoded_text)输出
[CLS] hello, how are you? [SEP]Model
Hugging Face 的 Model 用于加载和使用预训练的自然语言处理(NLP)模型。
加载预训练模型
Hugging Face 提供了多种预训练模型,可以通过 from_pretrained 方法加载。
from transformers import AutoModel
# 加载模型
model_name = "bert-base-uncased" # 例如:BERT 模型
model = AutoModel.from_pretrained(model_name)AutoModel 是一个通用类,可以根据模型名称自动推断并加载合适的模型架构。
想要具体的模型名称,打开Hugging Face Model Hub(Models - Hugging Face),使用搜索栏查找模型。例如,输入 "BERT"、"GPT-2" 或 "T5"。然后将你想要的模型输入进去即可(可以根据任务类型(如文本分类、问答、生成等)筛选模型)。
比较常见的模型名称如下:
BERT 系列
基于 Transformer 的编码器模型
bert-base-uncased: 不区分大小写的 BERT 基础模型。bert-large-uncased: 不区分大小写的 BERT 大模型。bert-base-cased: 区分大小写的 BERT 基础模型。bert-large-cased: 区分大小写的 BERT 大模型。
常见用途为:
文本分类
问答任务
命名实体识别
GPT 系列
基于 Transformer 的解码器模型
gpt2: GPT-2 模型。gpt2-medium: GPT-2 中等规模模型。gpt2-large: GPT-2 大规模模型。gpt2-xl: GPT-2 超大规模模型。
常见用途为:
文本生成
对话系统
T5 系列
基于 Transformer 的序列到序列模型
t5-small: T5 小模型。t5-base: T5 基础模型。t5-large: T5 大模型。t5-3b: T5 30亿参数模型。
常见用途为:
文本生成
翻译
摘要生成
RoBERTa 系列
BERT 的改进版本
roberta-base: RoBERTa 基础模型。roberta-large: RoBERTa 大模型。
常见用途为:
文本分类
问答任务
DistilBERT 系列
BERT 的轻量级版本,保留了大部分性能但模型更小、更快
distilbert-base-uncased: 不区分大小写的 DistilBERT 基础模型。
常见用途为:
文本分类
问答任务
BART 系列
序列到序列模型
facebook/bart-base: BART 基础模型。facebook/bart-large: BART 大模型。
常见用途为:
文本生成
摘要生成
在下载模型时请注意网络环境。如果想加载本地模型,只需要将model_name中替换成模型路径即可。
更改模型默认下载位置
前面提到了模型的默认下载位置,其实可以通过from_pretrained中的 cache_dir 参数来指定模型下载到哪里,例子如下:
from transformers import AutoModel
# 加载模型
model_name = "bert-base-uncased" # 例如:BERT 模型
model = AutoModel.from_pretrained(model_name, cache_dir="./save_model")推理
在模型推理之前,你需要将文本数据转换为模型可以理解的格式。这个步骤就是上一节说的分词器(Tokenizer)的工作(注意要将分词后的结果变成张量,一般是pytorch的张量):
# 输入文本
text = "Hello, how are you?"
# 使用分词器处理文本
inputs = tokenizer(text, return_tensors="pt")将处理后的输入传递给模型进行推理,根据任务的不同,模型的输出也会有所不同。
# 模型推理
outputs = model(**inputs)
# 获取预测结果
logits = outputs.logits
predictions = logits.argmax(dim=-1)
print(predictions)outputs:模型的输出对象,通常包含以下属性:
logits:模型的原始输出(未经过 softmax 或 sigmoid 的值)。hidden_states(可选):所有隐藏层的输出。attentions(可选):注意力权重。
微调模型
如果你有特定的任务和数据集,你可以对预训练模型进行微调。用Trainer和TrainingArguments可以进行训练以及调参,以下是一个简单的例子:
from transformers import Trainer, TrainingArguments
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
)
# 定义 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
)
# 开始训练
trainer.train()基本的训练步骤为:
定义
TrainingArguments,设置必要的训练参数定义
Trainer,将模型、TrainingArguments、数据集交给Trainer开始训练
TrainingArguments 类用于定义训练过程中的各种参数。以下是一些常用参数及其作用(更详细的参数请查看官方文档:https://huggingface.co/docs/transformers/v4.49.0/en/main_classes/trainer#transformers.TrainingArguments)
output_dir(str):
模型和日志的输出目录。训练完成后,模型、检查点和日志会保存到这里。per_device_train_batch_size(int):
每个设备(如 GPU 或 CPU)上的训练批次大小。per_device_eval_batch_size(int):
每个设备上的评估批次大小。num_train_epochs(float):
训练的轮数(epoch)。learning_rate(float):
初始学习率。weight_decay(float):
权重衰减(L2 正则化)系数,用于防止过拟合。logging_dir(str):
日志输出目录(如 TensorBoard 日志)。logging_steps(int):
每隔多少步记录一次日志。save_steps(int):
每隔多少步保存一次模型。eval_strategy(str):
评估策略,可选值:"no": 不进行评估。"steps": 每隔eval_steps步评估一次。"epoch": 每个 epoch 结束时评估一次。
eval_steps(int):
如果eval_strategy="steps",则每隔多少步评估一次。warmup_steps(int):
预热步数,用于学习率调度。在训练开始时,学习率会从 0 线性增加到初始学习率。fp16(bool):
是否使用混合精度训练(16 位浮点数),可以加速训练并减少显存占用。seed(int):
随机种子,用于复现实验结果。metric_for_best_model(str):
用于选择最佳模型的指标名称(如"eval_loss"或"accuracy")。训练过程中会根据该指标保存最佳模型。greater_is_better(bool):
如果metric_for_best_model的值越大越好(如准确率),则设置为True;如果越小越好(如损失),则设置为False。load_best_model_at_end(bool):
是否在训练结束时加载最佳模型。save_total_limit(int):
最多保存的检查点数量。超过该数量时,旧的检查点会被删除。push_to_hub(bool):
是否将模型推送到 Hugging Face Hub。resume_from_checkpoint(str):
从指定检查点恢复训练。
下面是个例子:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
num_train_epochs=3,
eval_strategy="steps",
eval_steps=500,
save_steps=500,
logging_steps=10,
learning_rate=5e-5,
weight_decay=0.01,
warmup_steps=500,
fp16=True,
metric_for_best_model="accuracy",
greater_is_better=True,
load_best_model_at_end=True,
save_total_limit=2,
push_to_hub=False
)Trainer 类封装了训练、评估和预测的逻辑。它简化了训练过程,并提供了许多高级功能。以下是一些常用参数及其作用(更详细的参数请查看官方文档:https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Trainer)
model(PreTrainedModel):
要训练的模型(如BertForSequenceClassification)。args(TrainingArguments):TrainingArguments对象,包含训练参数。train_dataset(Dataset):
训练数据集。eval_dataset(Dataset):
评估数据集。compute_metrics(Callable):
用于计算评估指标的函数。该函数接收eval_pred(包含预测值和真实值)并返回一个字典(如{"accuracy": 0.95})。tokenizer(PreTrainedTokenizer):
用于数据预处理的 tokenizer。data_collator(DataCollator):
用于将数据整理成批次的函数(如DataCollatorWithPadding)。callbacks(List[TrainerCallback]):
回调函数列表,用于在训练过程中执行自定义操作(如早停、日志记录等)。常用的回调函数包括:EarlyStoppingCallback: 早停回调,当指标不再提升时停止训练。TensorBoardCallback: 将日志记录到 TensorBoard。WandbCallback: 将日志记录到 Weights & Biases。
optimizers(Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]):
自定义优化器和学习率调度器。preprocess_logits_for_metrics(Callable):
在计算指标前对 logits 进行预处理的函数。compute_loss(Callable):
自定义损失函数。
下面是个例子:
from transformers import Trainer, EarlyStoppingCallback
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
tokenizer=tokenizer,
data_collator=DataCollatorWithPadding(tokenizer),
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)] # 早停回调
)保存和加载模型
训练完成后,你可以保存模型:
# 保存模型
trainer.save_model("./output/train_result")训练完毕后,大多数情况下会生成以下三个文件,它们的名字和作用分别是:
config.json
用途: 保存模型的配置信息,包括模型的结构、超参数和 tokenizer 的设置。
内容:
模型类型(如
"BertForSequenceClassification")。模型的超参数(如隐藏层大小、注意力头数等)。
Tokenizer 的配置(如词汇表大小、最大序列长度等)。
作用: 在加载模型时,
config.json用于重建模型的结构。
training_args.bin
用途: 保存训练时使用的
TrainingArguments参数。内容:
训练的超参数(如学习率、批次大小、训练轮数等)。
训练日志和检查点的配置。
作用: 在恢复训练或分析训练配置时使用。
model.safetensors
用途: 保存模型的权重参数。
内容:
模型的所有可训练参数(如权重矩阵、偏置等)。
作用: 在加载模型时,
model.safetensors用于加载模型的权重。
在加载模型时,我们只需要将这一整个文件夹加载进去即可(使用默认分词器):
from transformers import AutoModelForSequenceClassification, AutoTokenizer
module_name = "bert-base-uncased"
cache_model_dir = "./output/model_cache"
module_dir = "./output/train_result"
label_dict = {0: "sadness", 1: "happy", 2: "love", 3: "anger", 4: "fear", 5: "surprise"}
input_text = "The water is so cold today"
bert_tokenizer = AutoTokenizer.from_pretrained(module_name, cache_dir=cache_model_dir)
bert_model = AutoModelForSequenceClassification.from_pretrained(module_dir, num_labels=6)
# 对输入文本进行编码
input = bert_tokenizer(input_text, return_tensors="pt")
# 推理并预测结果
output = bert_model(**input)
predict_labels = output.logits.argmax(dim=-1).item()
print(f"The predicted emotion for the text '{input_text}' is: {label_dict[predict_labels]}")