
pandas初识
pandas 是一个开源的 Python 库,用于处理和分析数据。它提供了高效的数据结构和数据分析工具,可以让你快速处理和分析数据。
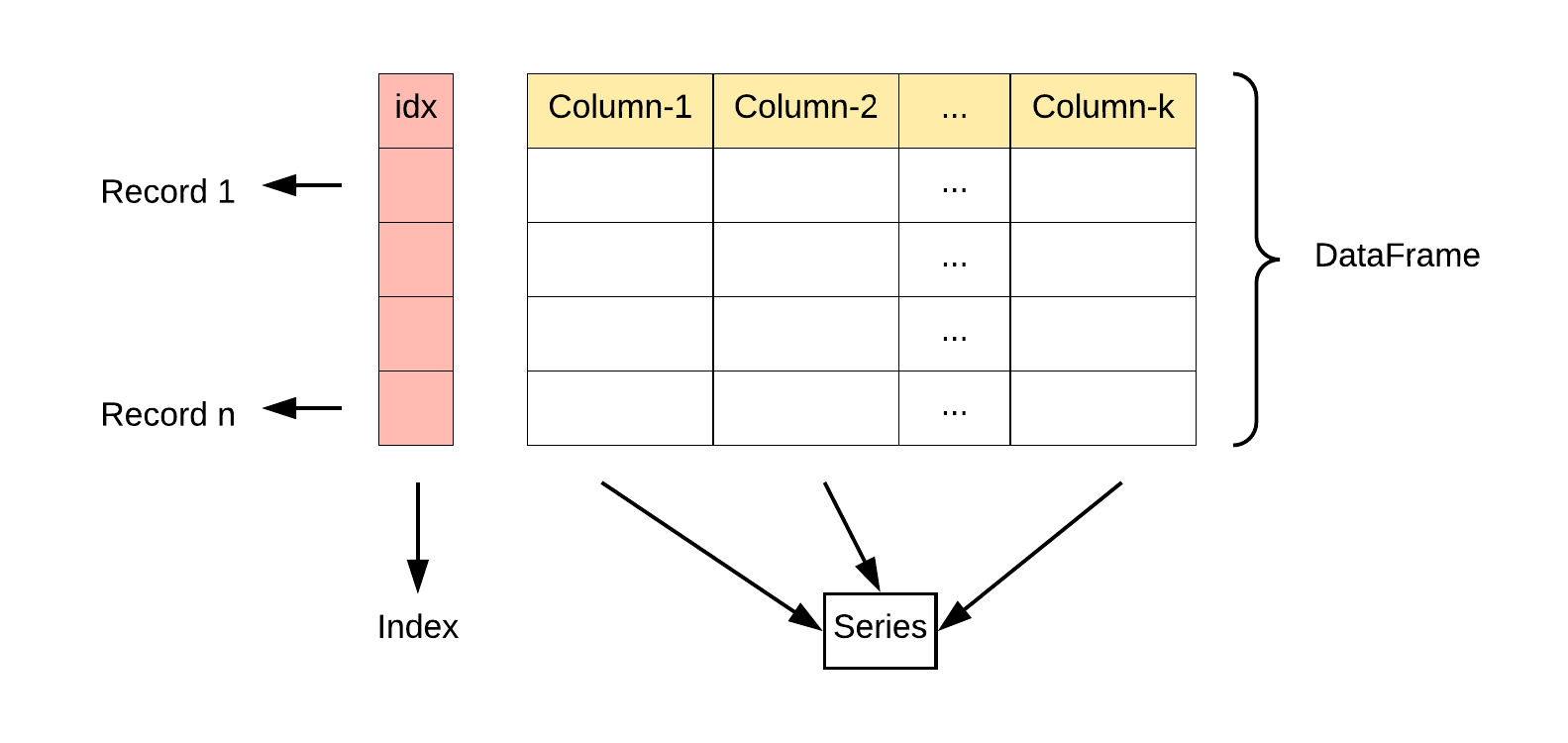
pandas 主要包含两种数据结构:Series 和 DataFrame。
Series:表示一维数组,类似于一列表格中的数据。DataFrame:表示二维数组,类似于表格或电子表格中的数据。
pandas 还提供了大量的工具来处理和分析数据,例如:
读取和写入各种数据文件格式(如 CSV、Excel、JSON 等)。
对数据进行筛选、排序、去重、聚合等操作。
处理缺失数据。
数据转换和转换时间序列数据。
基本的统计分析和数据可视化功能。
此外,pandas 还与其他的数据分析库(如 NumPy 和 SciPy)很好地集成,可以提供更强大的数据分析功能。
总的来说,pandas 是一个非常强大且易于使用的数据处理和分析工具,可以大大简化数据处理和分析的工作。
安装
pip install pandas引入
import pandas as pdPandas数据结构--Series
Pandas 的 Series 是一种一维的数据结构,类似表格中的一个列(column),也类似于一维数组。它可以包含不同类型的数据,并且每个数据都有一个与之对应的索引标签。函数如下:
pandas.Series(data, index, dtype, name, copy)参数说明:
data:一组数据(可以是列表或numpy.ndarray数据类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
例如,我们可以用一个 Series 来存储一组人的姓名和年龄:
import pandas as pd
ages = pd.Series([25, 30, 35, 40], index=['Alice', 'Bob', 'Charlie', 'Dave'])
print(ages)输出结果,左边的是索引,右边的是数据,dtype: int64指示数据类型:
Alice 25
Bob 30
Charlie 35
Dave 40
dtype: int64这样,我们就可以通过索引来访问 Series 中的数据,例如:
print(ages['Alice']) # 25
print(ages[['Alice', 'Charlie']]) # Alice 25
# Charlie 35
# dtype: int64除了通过索引访问数据,我们还可以使用类似数组的方式访问数据,例如:
print(ages[0]) # 25
print(ages[:2]) # Alice 25
# Bob 30
# dtype: int64我们还可以对 Series 中的数据进行运算,例如:
print(ages * 2) # Alice 50
# Bob 60
# Charlie 70
# Dave 80
# dtype: int64Series常用函数
head()、tail(): 可以用来查看 Series 的前几个或后几个元素。
print(ages.head()) # Alice 25
# Bob 30
# Charlie 35
# Dave 40
# dtype: int64
print(ages.tail()) # Alice 25
# Bob 30
# Charlie 35
# Dave 40
# dtype: int64mean()、median(): 可以用来计算 Series 的平均值和中位数。
print(ages.mean()) # 32.5
print(ages.median()) # 32.5unique(): 可以用来查看 Series 中有多少个不同的元素,以及这些元素是什么。
print(ages.unique()) # [25 30 35 40]value_counts(): 可以用来计算 Series 中每个元素出现的次数。
print(ages.value_counts()) # 30 1
# 40 1
# 35 1
# 25 1
# dtype: int64Pandas数据结构--DataFrame
Pandas 的 DataFrame 是一种二维的数据结构,类似于excel表格中的数据,它可以包含不同类型的数据,并且每一行和每一列都有一个与之对应的索引标签。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
注意,没有对应的部分数据为 NaN,类型是float。
索引
Pandas DataFrame 的索引是 DataFrame 中用于确定行和列位置的标签。索引可以是整数或字符串。默认情况下,Pandas 为每个 DataFrame 创建一个整数索引,但可以通过设置 "index" 参数来指定其他类型的索引。
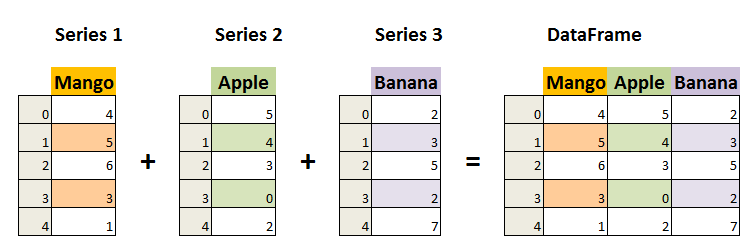
上面的例子中Mango、Apple、Banana就是索引,pandas dataframe中索引的分类具体可以分为两类:
行索引(row index):每行数据在 DataFrame 中的唯一标识,默认情况下是整数索引。
列索引(column index):每列数据在 DataFrame 中的唯一标识,可以是字符串或整数索引。
Pandas DataFrame 中的索引可以是多种数据类型,常见的类型包括:
整数索引:默认情况下,Pandas 为每个 DataFrame 创建一个整数索引。
字符串索引:在某些情况下,可能需要将字符串作为索引,例如使用列名作为索引。
布尔索引:类似于条件语句的方式,其中一个或多个布尔值用于筛选 DataFrame 中的行或列。
时间索引:可以使用时间戳或日期作为索引,例如在时间序列分析中。
带有重复标签的索引: 可以使用重复的标签作为索引,但这会导致索引不唯一。
层次化索引 (MultiIndex): 多重索引组成的索引,可以用于在 DataFrame 的行或列上实现多层级结构。
新建DataFrame对象
DataFrame 构造方法如下:
pandas.DataFrame(data, index, columns, dtype, copy)参数说明:
data:一组数据(ndarray、series, map, lists, dict等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
例如,我们可以用一个 DataFrame 来存储一组人的姓名、年龄和职业:
import pandas as pd
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'Dave'],
'age': [25, 30, 35, 40],
'occupation': ['Engineer', 'Doctor', 'Teacher', 'Lawyer']
})
print(df)输出结果:
name age occupation
0 Alice 25 Engineer
1 Bob 30 Doctor
2 Charlie 35 Teacher
3 Dave 40 Lawyer查看Dataframe属性
查看dataframe的形状(行列)
dataframe实际上是一个矩阵,如果想知道dataframe有多少行,多少列,可以调用shape属性查看dataframe的形状
import pandas as pd
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'Dave'],
'age': [25, 30, 35, 40],
'occupation': ['Engineer', 'Doctor', 'Teacher', 'Lawyer']
})
print(df)
print(df.shape)输出结果:
name age occupation
0 Alice 25 Engineer
1 Bob 30 Doctor
2 Charlie 35 Teacher
3 Dave 40 Lawyer
(4, 3)返回的结果是一个元组,第一个元素是行,第二个元素是列
查看dataframe的数据类型
如果想看dataframe的所有列的数据类型,使用dtypes属性查看dataframe的形状
import pandas as pd
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'Dave'],
'age': [25, 30, 35, 40],
'occupation': ['Engineer', 'Doctor', 'Teacher', 'Lawyer']
})
print(df)
print(df.dtypes)输出结果:
name age occupation
0 Alice 25 Engineer
1 Bob 30 Doctor
2 Charlie 35 Teacher
3 Dave 40 Lawyer
name object
age int64
occupation object
dtype: object如果想要查看某一列的数据类型,写法如下:
print(df["name"].dtypes) # object查看dataframe的索引
查看行索引:
df.index
list(df.index) # [0, 1, 2, 3]查看列索引:
df.columns
list(df.columns) # ['name', 'age', 'occupation']
list(df) # 这样的写法也可以查看dataframe是否为空
查看某列是否为空:
df["age"].empty # True按列访问数据
我们就可以通过列索引来访问 DataFrame 中相应列的数据,语法为:
df[column_index]column_index为列索引,通常为字符串。例如:
print(df['name']) # 0 Alice
# 1 Bob
# 2 Charlie
# 3 Dave
# Name: name, dtype: object
print(df[['name', 'age']]) # name age
# 0 Alice 25
# 1 Bob 30
# 2 Charlie 35
# 3 Dave 40可以将列数据转换成list,方法如下:
print(df['name'].tolist()) # 将索引为name的数据转换成为list如果不知道列名,可以按位置来访问:
first_column = df.iloc[:, 0] # 访问第一列,注意这里使用':'表示选取所有行,0表示第一列按行访问数据
我们可以使用类似于数组的方式(按行)访问数据,DataFrame.loc和DataFrame.iloc是在pandas DataFrame中访问行数据的两种常用方式。
iloc的一般语法为:
df.iloc[row_indexer, col_indexer]row_indexer: 表示行的整数位置col_indexer: 表示列的整数位置(可选)
可以传入单个整数来选择某行数据,也可以传入切片来选择多行多列。所有的操作下标都是从0开始。例如:
# 获取第一行的数据
print(df.iloc[0]) # name Alice
# age 25
# occupation Engineer
# Name: 0, dtype: object
# 获取第一行,第二列(单元格)的数据
print(df.iloc[0,1]) # 25
# 获取第一行到第二行的数据
print(df.iloc[1:3]) # name age occupation
# 1 Bob 30 Doctor
# 2 Charlie 35 Teacher除了iloc,还有一个loc,DataFrame.loc 使用的是标签索引,可以使用行和列的标签来访问数据。loc的语法为:
df.loc[row_label, col_label]row_label: 表示行的标签col_label: 表示列的标签
# 获取第一行的数据
print(df.loc[0]) # name Alice
# age 25
# occupation Engineer
# Name: 0, dtype: object
# 获取第一行,第二列(单元格)的数据
print(df.loc[0, "age"]) # 25
# 获取第一行到第三行的数据(注意和iloc不同)
print(df.loc[1:3]) # name age occupation
# 1 Bob 30 Doctor
# 2 Charlie 35 Teacher
# 3 Dave 40 Lawyer前面我们知道了怎么获取列数据,为了获取某单元格数据(假设获取Alice这个数据,第一行,第一列),有以下办法:
# 索引名+iloc/loc
df["name"].iloc[0]
df["name"].loc[0]
# iloc[行, 列]
df.iloc[0, 0]
# loc[行, 索引名](推荐做法)
df.loc[0, "name"]可以将行数据转换成list:
print(df.iloc[0].tolist()) # 将第一行的数据转换成为list
print(df.loc[0].tolist()) # 将第一行的数据转换成为list按列数据匹配
精准匹配
当我们得到一个DataFrame的时候,若想要寻找某列下的某个数据,可以使用pandas的布尔索引进行匹配,语法如下:
df[df[row_index] == value]或者
df.loc[df[row_index] == value]例如:
print(df['name'] == 'Alice')
print(df[df['name'] == 'Alice'])
print(df.loc[df['name'] == 'Alice'])得到结果:
0 True
1 False
2 False
3 False
Name: name, dtype: bool
name age occupation
0 Alice 25 Engineer
Name: name, dtype: bool
name age occupation
0 Alice 25 Engineer除了以上办法,还有如下方法对数据进行匹配:
使用query()方法
row_index = "name"
value = "Alice"
result = df.query(f"{row_index} == '{value}'")
print(result)使用DataFrame的apply()方法和lambda函数,例如
result = df[df.apply(lambda x: x['name'] == 'Alice', axis=1)]
print(result)使用DataFrame的groupby()方法,例如
result = df.groupby('name').get_group('Alice')
print(result)使用DataFrame的where()方法,例如
result = df.where(df['name'] == 'Alice')
print(result)模糊搜索
当我们得到一个DataFrame的时候,若想要寻找某列下的某个数据,但是我们不知道准确的value,可以使用Pandas的str属性和正则表达式来进行模糊搜索,其本质也是利用了pandas的布尔索引。
首先是str属性,str属性常用的方法如下:
df[row_index].str.contains(value): 查找某列中包含value的行,返回True和False,True为匹配成功,False为失败df[row_index].str.find(value): 查找某列中包含value的行,返回0和-1,0为匹配成功,-1为失败df[row_index].str.startswith(value): 查找某列中以value开头的行df[row_index].str.endswith(value): 查找某列中以value结束的行
例如:
# 查找某列中包含value的行,返回True和False,True为匹配成功,False为失败
print(df['name'].str.contains('Al'))
print(df[df['name'].str.contains('Al')])
# 查找某列中包含value的行,返回0和-1,0为匹配成功,-1为失败
print(df['name'].str.find('Al'))
print(df[df['name'].str.find('Al') != -1]) # 注意变成布尔索引
# 查找某列中以value开头的行
print(df['name'].str.startswith('Al'))
print(df[df['name'].str.startswith('Al')])
# 查找某列中以value结束的行
print(df['name'].str.endswith('ce'))
print(df[df['name'].str.endswith('ce')])输出结果:
0 True
1 False
2 False
3 False
Name: name, dtype: bool
name age occupation
0 Alice 25 Engineer
0 0
1 -1
2 -1
3 -1
Name: name, dtype: int64
name age occupation
0 Alice 25 Engineer
0 True
1 False
2 False
3 False
Name: name, dtype: bool
name age occupation
0 Alice 25 Engineer
0 True
1 False
2 False
3 False
Name: name, dtype: bool
name age occupation
0 Alice 25 Engineer其中df[row_index].str.contains(value)支持使用正则表达式,value中传入re.compile()即可。例如查找名字中包含"A"或者"B"的行
import re
print(df['name'].str.contains(re.compile("A|B")))
print(df[df['name'].str.contains(re.compile("A|B"))])结果:
0 True
1 True
2 False
3 False
Name: name, dtype: bool
name age occupation
0 Alice 25 Engineer
1 Bob 30 Doctor条件匹配
当我们得到一个DataFrame的时候,若想要寻找某列下的某个int或float类型的数据,我们不能像上面使用str属性,这个时候我们可以通过条件去匹配对应的数据,其本质也是利用了pandas的布尔索引。
比如,找出年龄大于30岁的数据,写法如下:
print(df['age'] > 30)
print(df[df['age'] > 30])输出结果:
0 False
1 False
2 True
3 True
Name: age, dtype: bool
name age occupation
2 Charlie 35 Teacher
3 Dave 40 Lawyer也可以通过运算后输入条件,比如:
print(df['age']+10 <= 40)
print(df[df['age']+10 <= 40])0 True
1 True
2 False
3 False
Name: age, dtype: bool
name age occupation
0 Alice 25 Engineer
1 Bob 30 Doctor如果想要精确匹配,和字符串一样使用==符号寻找即可。比如找出30岁的人的信息:
print(df['age'] == 30)
print(df[df['age'] == 30])0 False
1 True
2 False
3 False
Name: age, dtype: bool
name age occupation
1 Bob 30 Doctor数字运算
我们可以对DataFrame中的数据进行运算,例如:
print(df['age'] * 2) # 0 50
# 1 60
# 2 70
# 3 80
# Name: age, dtype: int64
print(df['age'] + df['age']) # 0 50
# 1 60
# 2 70
# 3 80
# Name: age, dtype: int64dataframe自带了一些api可以对dataframe进行运算,比如说求平均值:
print(df['age'].mean()) # 32.5对于其他的运算,数据的聚合与排序这一章进行了详细的说明
行列操作
增删行列
在Pandas中,可以使用以下方法对DataFrame的行或列进行增删:
增加行:可以使用
.loc和.iloc属性来增加新行,也可以使用append()函数来增加新行。删除行:可以使用
drop()函数来删除行。增加列:可以使用列表或
.assign()函数来增加新列。删除列:可以使用
drop()函数来删除列。
示例代码如下:
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'], 'Age':[28,34,29,42], 'Salary':[70000, 45000, 50000, 60000]}
df = pd.DataFrame(data)
#增加行
df.loc[4] = ['Bob', 25, 60000]
#删除行
df = df.drop(3)
#增加列
df['Country'] = ['US', 'US', 'UK', 'AU']
#删除列
df = df.drop('Country', axis=1)修改单元格数据
dataframe的数据是可修改的。我们可以对单元格的某个数据重新赋值,例如:
print(df.loc[0, "age"]) # 25
df.loc[0, "age"] = 30
print(df.loc[0, "age"]) # 30修改列数据
我们想要对列进行修改,可以进行下面的操作
print(df["age"])
df["age"] = df["age"]+20
print(df["age"])输出结果:
0 25
1 30
2 35
3 40
Name: age, dtype: int64
0 45
1 50
2 55
3 60
Name: age, dtype: int64修改列数据的关键是重新赋值,也就是df["age"] = df["age"]+20这个操作,df["age"]可以看作一个变量,重新赋值可以让列的数据改成我们想要的数。
也可以通过apply调用函数对一列的数据进行修改
# 应用上面定义的函数到'Numbers'列
df['Numbers'] = df['Numbers'].apply(double_if_less_than_10)修改数据类型
在我们想要修改dataframe的数据类型时,我们需要用到astype这个方法并重新赋值即可修改dataframe的数据类型
比如修改某一列的数据类型:
print(df["age"].dtypes) # int64
df["age"] = df["age"].astype(str)
print(df["age"].dtypes) # object若想修改整个dataframe的数据类型,方法与上面大同小异:
print(df.dtypes)
df = df.astype(str)
print(df.dtypes)name object
age int64
occupation object
dtype: object
name object
age object
occupation object
dtype: object重命名行列索引名
在我们想要修改dataframe的行列索引名时,可以用df.rename()对行列索引名进行重命名。
df.rename()的语法如下:
df.rename(columns={原列索引名: 新列索引名}, inplace=False)
df.rename(index={原行索引名: 新行索引名}, inplace=False)可以看到rename以字典的方式标识新旧索引名,inplace如果为True则自动进行重赋值操作,不需要用户手动重赋值
比如需要修改某个列索引名:
print(df)
df.rename(columns={"name":"name64","age":"age64"}, inplace=True)
# 等价于 df = df.rename(columns={"name":"name64","age":"age64"})
print(df)输出:
name age occupation
0 Alice 25 Engineer
1 Bob 30 Doctor
2 Charlie 35 Teacher
3 Dave 40 Lawyer
name64 age64 occupation
0 Alice 25 Engineer
1 Bob 30 Doctor
2 Charlie 35 Teacher
3 Dave 40 Lawyer修改某个行索引名:
print(df)
df.rename(index={0:"alice_0",1:"bob_1"}, inplace=True)
# 等价于 df = df.rename(index={0:"alice_0",1:"bob_1"})
print(df)输出:
name age occupation
0 Alice 25 Engineer
1 Bob 30 Doctor
2 Charlie 35 Teacher
3 Dave 40 Lawyer
name age occupation
alice_0 Alice 25 Engineer
bob_1 Bob 30 Doctor
2 Charlie 35 Teacher
3 Dave 40 Lawyer分组
可以对DataFrame进行分组,使用groupby()函数即可,语法格式如下:
df.groupby(by, axis, level, as_index, sort, group_keys, squeeze, observed)其中,by 参数表示分组依据的列名或列索引,可以是一个字符串或列表。
示例代码如下:
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42],'Salary':[70000, 45000, 50000, 60000]}
df = pd.DataFrame(data)
# 按照名字分组
grouped = df.groupby('Name')
print(grouped.mean())首先,使用df.groupby('Name')按照Name列来分组 其次,使用grouped.mean()来计算每组的平均值。您也可以使用 groupby 函数配合其他聚合函数来实现对分组数据的汇总和统计。
切片
按行切片
first_three_rows = df.iloc[:3] # 选取前3行, 数字代表数量,从第一行开始切
rows_2_to_4 = df.iloc[1:4] # 选取第2行(从0开始)到第4行(下标为第二个数字-1), Python的切片是左闭右开区间,会返回下标1 -> 3的行
every_other_row = df.iloc[::2] # 每间隔一行选取, 第三个数字为行间距, 数字-1
# 可以结合使用
every_other_rows_2_to_4 = df.iloc[1:4:2] # 每间隔一行选取第2行到第4行以上代码同等替换为:
first_three_rows = df[:3] # 选取前3行, 数字代表数量,从第一行开始切
rows_2_to_4 = df[1:4] # 选取第2行(从0开始)到第4行(下标为第二个数字-1), Python的切片是左闭右开区间,会返回下标1 -> 3的行
every_other_row = df[::2] # 每间隔一行选取, 第三个数字为行间距, 数字-1
# 可以结合使用
every_other_rows_2_to_4 = df[1:4:2] # 每间隔一行选取第2行到第4行可以按条件切片
df[df["A"] > 5] # 一个条件
df[(df["A"] > 5) & (df["B"] > 3)] # 逻辑运算符 &(与)、|(或)来组合多个条件,注意每个条件都要用括号包起来
# 可以使用条件函数
values_to_match = [1, 3]
df[df['A'].isin(values_to_match)]按列切片
可以一次选择多个列:
df[["A", "B", "C"]] # 选择多列
specific_columns = df.iloc[:, [0, 2]] # 选取特定位置的多列,比如第一列和第三列对列进行切割
first_column = df.iloc[:, 0] # 选取第一列
first_two_columns = df.iloc[:, :2] # 选取两列, 该数字代表数量
columns_2_to_4 = df.iloc[:, 1:4] # 第2列(从0开始)到第4列(下标为第二个数字-1),Python的切片是左闭右开区间,会返回下标1 -> 3(数字索引,主观上的第xx行)的列
every_other_columns = df[:, ::2] # 每间隔一列选取, 第三个数字为行间距, 数字-1
# 可以结合使用
every_other_columns_2_to_4 = df[:, 1:4:2] # 每间隔一列选取第2列到第4列可以按条件切片
not_A = df.iloc[:,df.columns != "A"] # 排除特定列进行刷选
just_A = df.iloc[:,df.columns == "A"] # 只选择特定列