
决策树--揭开机器学习中“智慧树”的神秘面纱
决策树是一种广泛应用于机器学习和数据分析领域的预测建模方法,尤其适用于分类和回归问题。其核心思想是通过一系列规则(if-then逻辑)将复杂的数据集逐步分割,形成一个树状结构,以直观地表示数据的分类或数值预测过程。
决策树是树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。对于非纯的叶节点,多数类的标号给出到达这个节点的样本所属的类。构造决策树的核心问题是在每一步如何选择适当的属性对样本做拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下,分而治之的过程。
在学习决策树之前,请了解数据结构--树,网址如下:
以下文章的代码都用Python使用scikit-learn库构建决策树
决策树的构建过程
决策树(decision tree)是一类常见的机器学习方法。以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类吗?”
这个问题的“决策”或“判定”过程,顾名思义,决策树是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制。
例如,我们要对“这是好瓜吗?”这样的问题进行决策时,通常会进行一系列的判断或“子决策”:我们先看“它是什么颜色?”,如果是“青绿色”,则我们再看“它的根蒂是什么形态?”,如果是“蜷缩”,我们再判断“它敲起来是什么声音?”,最后,我们得出最终决策:这是个好瓜。
这个决策过程如图所示:
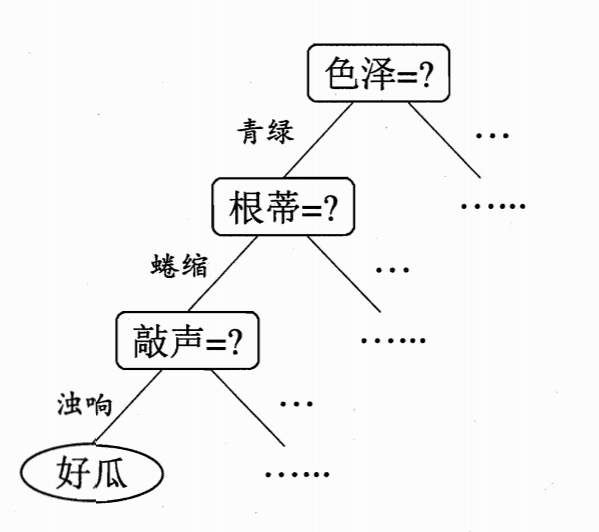
一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;
叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集。
从根结点到每个叶结点的路径对应了一个判定测试序列。
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之”(divide-and-conquer)策略。
划分选择
不难看出,决策树学习的关键是如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。如何划分才能够更有效增加每个节点的纯度,下面是常用的几种办法
信息增益(ID3算法)
信息熵(information entropy)是度量样本集合纯度最常用的一种指标,用来量化信息的不确定性。
其核心算法是,根据样本子集属性取值的信息增益值的大小来选择决策属性(即决策树的非叶子结点),并根据该属性的不同取值生成决策树的分支,再对子集进行递归调用该方法,当所有子集的数据都只包含于同一个类别时结束。最后,根据生成的决策树模型,对新的、未知类别的数据对象进行分类。
假定当前样本集合D中第k类样本所占的比例为p_k = (k = 1, 2, ..., |y|),则D的信息熵定义为:
Ent(D)的值越小,则D的纯度越高
假定离散属性α有V个可能的取值\{a^1, a^2, ... , a^V\},若使用α来对样本集D进行划分,则会产生V个分支结点
其中第个分支结点包含了D中所有在属性α上取值为a^v的样本,记为D^v
再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重|D^v|/|D|,即样本数越多的分支结点的影响越大,于是可计算出用属性α对样本集D进行划分所获得的“信息增益“(information gain)
一般而言,信息增益越大,则意味着使用属性α来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择。
增益率(C4.5算法)
ID3算法存在一个问题,就是偏向于取值数目较多的属性
例如:如果存在一个唯一标识,这样样本集D将会被划分为|D|个分支,每个分支只有一个样本,这样划分后的信息熵为零,十分纯净,但是对分类毫无用处。
C4.5算法是ID3的一个改进算法,继承了ID3算法的优点。使用信息增益率作为分裂规则(需要用信息增益除以,该属性本身的熵),此方法避免了ID3算法中的归纳偏置问题,因为ID3算法会偏向于选择类别较多的属性(形成分支较多会导致信息增益大)。多分叉树。连续属性的分裂只能二分裂,离散属性的分裂可以多分裂,比较分裂前后信息增益率,选取信息增益率最大的。
增益率定义为:
其中:
属性a的取值越大,IV(a)越大
基尼指数(CART算法)
CART的全称为(Classification And Regression Tree),即分类回归树(只能形成二叉树)
采用的是基尼(Gini)指数(选Gini指数最小的特征s)作为分裂标准,同时它也是包含后剪枝操作
ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支较大,规模较大
为了简化决策树的规模,提高生成决策树的效率,就出现了根据基尼系数来选择测试属性的决策树算法CART
直观来说,Gini(D)反映了数据集D中随机抽样两个样本,其类别标记不一致的概率。
因此,Gini(D)越小,则数据集D的纯度越高
进而,使用属性a划分后的基尼指数为:
决策树的优点与局限性
与众多算法一样,决策树也有优点以及局限性:
优点:
易解释性与可视化:决策树模型通过树状结构展示决策过程,便于非专业人士理解,有助于决策分析和知识传播。
处理多种类型数据:决策树能够同时处理数值型、分类型及混合属性,适应性强,广泛应用于不同领域。
无需数据预处理:算法对数据的缩放不敏感,不需要特征标准化或归一化,简化了数据预处理步骤。
特征选择:在构建过程中自动进行特征选择,排除不重要的特征,有助于提升模型性能并简化模型。
处理缺失值:具备较强的处理缺失数据的能力,可通过不同的策略如使用默认值、近邻值填充等方法处理缺失值。
高效处理大数据:对于大数据集,决策树算法能够快速高效地进行训练和预测。
适用范围广:既可用于分类问题,也可用于回归问题,具有较好的通用性。
其局限性:
决策边界限制:决策树的决策边界通常是与坐标轴平行的直线,这意味着复杂的决策边界(如斜线或曲线)难以精确表示,可能影响模型精度。
过拟合风险:决策树容易过度拟合训练数据,特别是在树的深度较大时。需要通过剪枝技术(预剪枝和后剪枝)来控制模型复杂度。
局部最优解:决策树算法采用贪心策略进行特征选择和分割,可能导致最终模型只是局部最优而非全局最优。
对噪声敏感:决策树对训练数据中的异常值或噪声很敏感,单个数据点的变化可能会显著改变决策边界。
复杂树难以交流:当决策树变得非常庞大时,其结构可能过于复杂,不易于与他人交流或理解。
缺乏概率估计:相比于其他模型(如贝叶斯分类器),决策树不直接提供概率预测,尽管可以通过一些方法(如对数几率变换)间接获得。
处理连续特征的局限:虽然决策树可以处理连续特征,但其处理方式通常涉及离散化,这可能损失信息。
python实践(决策分类树)
下载数据集
进入kaggle,下载泰坦尼克号乘客的数据集,url:Tatanic Train Data set (kaggle.com)
导入所需第三方库
下面是实践项目中需要用到的第三方库
import pandas as pd
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt载入数据集
使用pandas载入
df = pd.read_csv("./data/taitanic/data.csv")数据集拆分
首先我们需要区分特征以及标签,将Survived这一列设置为标签,其他皆为特征
X = df.iloc[:,df.columns != "Survived"]
Y = df.iloc[:,df.columns == "Survived"]将30%的数据拆分为测试数据,70%的数据拆分为训练数据:
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3) # 对数据进行拆分,拆分成训练集和测试集,其中测试集(test_size)约占总数据集的30%(test_size=0.3)
# 重置数据集索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])模型评估
在训练之前,我们需要对模型的准确率进行一定的评估,我们需要确定深度:
tr = []
te = []
epoch_times = 10
for epoch in range(epoch_times):
# max_depth=epoch+1 表示决策树的最大深度为epoch+1层
# criterion="entropy"表示使用信息熵作为划分标准
clf = DecisionTreeClassifier(random_state=25, max_depth=epoch+1, criterion="entropy")
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain, Ytrain)
score_te = cross_val_score(clf, X, Y, cv=10).mean()
tr.append(score_tr)
te.append(score_te)
plt.plot(range(1,epoch_times+1), tr, color="red",label="train")
plt.plot(range(1,epoch_times+1), te, color="blue",label="test")
plt.xticks(range(1, epoch_times+1))
plt.legend()
plt.show()模型训练
假设决策树最大深度为4时,准确率达到最高
clf = DecisionTreeClassifier(random_state=25, max_depth=4, criterion="entropy").fit(Xtrain, Ytrain) # random_state=25表示随机种子为25,确保每次运行结果一致
score_ = clf.score(Xtest, Ytest)
score = cross_val_score(clf, X, Y, cv=10).mean() # 交叉验证,cv=10表示将数据集拆分成10份,进行10次交叉验证。训练完毕,我们可以对其进行一个图片展示:
fig = plt.figure(figsize=(25,20))
plot_tree(
clf,
filled=True,
max_depth=4
)
# 保存图片
fig.savefig("taitanic_decistion_tree.png")