
从零开始:构建并训练自己的YOLO模型
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的约瑟夫-雷德蒙(Joseph Redmon)和阿里-法哈迪(Ali Farhadi)开发。YOLO于2015年推出,因其高速度和高精确度而迅速受到欢迎。
与传统的两阶段检测器(如R-CNN系列)不同,YOLO采用了一种端到端的单阶段方法,将检测视为一个回归问题,直接从全图像中同时推理边界框和类别概率。
YOLO因其高效和准确的特点,被广泛应用于多个领域,包括但不限于自动驾驶汽车、无人机视觉、安防监控系统以及医疗成像分析等。
网址导航:
安装
pytorch安装
在安装yolo之前,需要安装GPU版本的torch(除非没有显卡)
进入pytorch官网:Start Locally | PyTorch
若为CPU版本,则使用如下命令(直接在官网复制也可)直接安装即可
pip install torch torchvision torchaudio若为GPU版本,首先输入如下命令查看本机的cuda版本:
nvidia-smi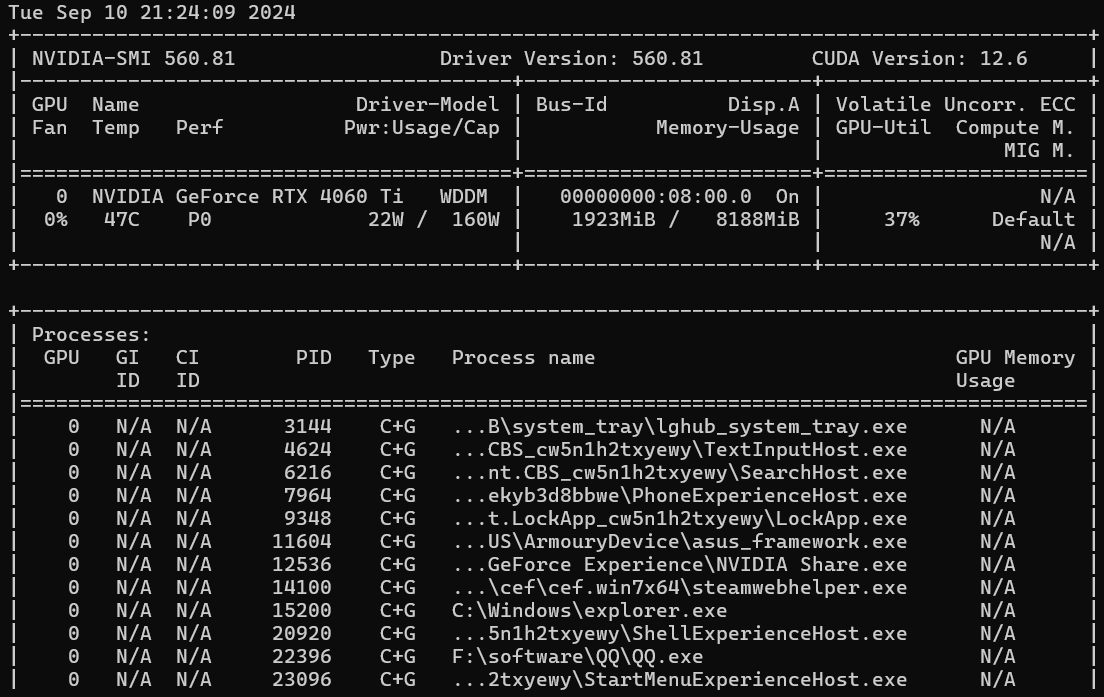
图中可以得知,cuda版本为12.6
之后在pytorch官网选择对应版本的pytorch安装即可(如果高于里面所有的版本,可以选择相对低一点的版本安装),例如pytroch官网中,支持的cuda最高版本为12.4,而本机cuda版本为12.6,则可以安装cuda版本为12.4的pytorch
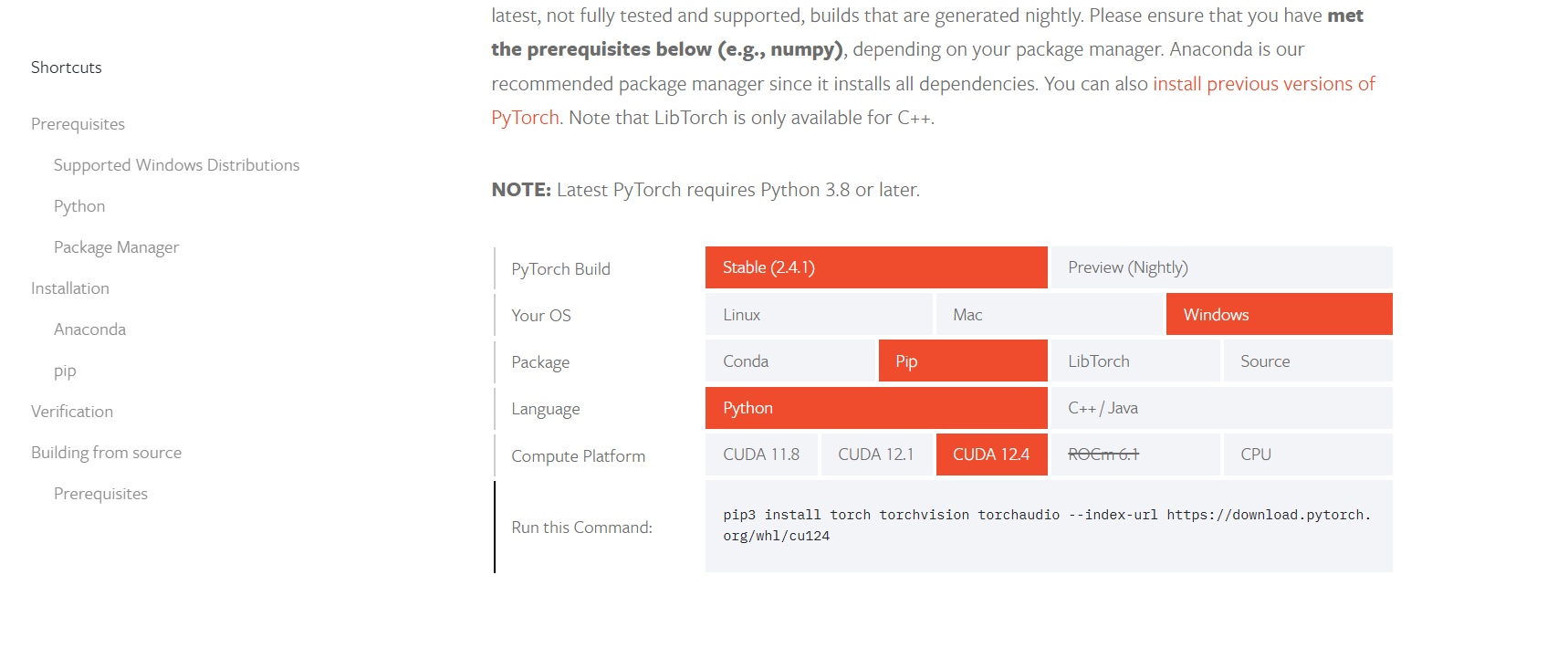
复制上面的命令即可(比较大,请耐心等待):
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124在安装完毕后,执行以下代码检查是否成功安装GPU版本的pytorch
import torch
print(torch.cuda.is_available()) # 为True则成功安装GPU版本的pytorchultralytics-YOLO安装
接下来安装YOLO,使用如下命令安装YOLO:
pip install ultralyticsultralytics是管理YOLO的团队,他们管理了大部分的YOLO版本,所以直接安装该库比较方便
安装完毕后,命令行使用yolo检查是否安装成功
Quick Start
为了快速认识YOLO,我们做两个例子
数据准备
使用如下网址下载数据集:
https://github.com/ultralytics/assets/releases/download/v0.0.0/coco8.zip更新设置
我们可以自定义设置数据集、权重和运行记录路径
在运行时会根据该位置寻找对应的资料
from ultralytics import settings
settings.update({
"datasets_dir": BaseProperty.datasets_path,
"weights_dir": BaseProperty.weights_path,
"runs_dir": BaseProperty.output_path,
})若想恢复为默认设置,则可以这样:
settings.reset()推理
执行如下代码推理,首先载入权重(进入ultralytics官方文档下载即可),然后执行推理:
from ultralytics import YOLO
model = YOLO("yolov11m.pt")
results = model.predict(FilePathUtils.path_joint_str(BaseProperty.datasets_path, "coco8", "images", "train", "000000000009.jpg"))
for result in results:
print(result.boxes.data)
result.show() # uncomment to view each result image训练
在datasets文件夹下放coco8.yaml和coco8数据集
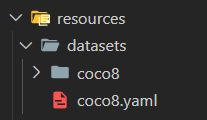
coco8.yaml中,将path这一项改成coco8。这里直接写datasets名字是因为,datasets的路径在上面的设置中指定了,系统会根据上面设置的路径去找到path中的coco8数据集
train和val的路径会在path的基础下寻找,假设为如下设置:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)train的路径会为:$datasets_dir/coco8/images/train
val的路径会为:$datasets_dir/coco8/images/val
接下来调用如下代码执行训练:
from ultralytics import YOLO
model = YOLO("yolov11n.yaml").load("yolov11n.pt")
results = model.train(data="coco8.yaml", epochs=100, workers=0)
print(results)注意:在windows平台中,workers要设置为0,如果不设置为0,则会报错(尚未找到解决的办法)。
任务
目前YOLO可使用如下几个任务
图像分类
图像分类是YOLO的一个基本任务,它用于识别图像中包含的对象类别。通过训练,YOLO模型能够对输入图像进行分类,并输出每个类别的概率。
目标检测
目标检测是YOLO的另一个重要任务,它不仅需要识别图像中的对象类别,还需要确定对象在图像中的具体位置。YOLO模型通过在图像中划分网格,并在每个网格单元中推理边界框和类别概率来实现这一任务。
实例分割
实例分割是目标检测的扩展,它不仅需要识别和定位图像中的对象,还需要为每个对象生成像素级别的分割遮罩。YOLO通过推理每个对象的边界框和物体遮罩来实现实例分割。
姿态检测
姿态检测是YOLO的一个高级任务,它用于识别和定位图像中人体的关键点,如关节和肢体位置。YOLO模型通过推理人体关键点的位置来实现这一任务。
OBB(Oriented Bounding Box)
OBB是目标检测的一个变种,它使用定向边界框来更准确地表示对象的形状。与传统的轴对齐边界框(AABB)相比,OBB能够更好地适应对象的实际方向和形状,从而提高检测的准确性。
支持的YOLO版本
YOLO的不同版本会支持不同的任务,也有一些版本是所有的任务都可以支持
支持以上所有任务的YOLO版本如下:
YOLOV8
YOLOV11
如果想查看某个特定的YOLO版本支持的任务,可以查看该版本的官方文档: https://docs.ultralytics.com/models/
以下教程皆以YOLOV11为例
模型加载
不同的模型支持不同的任务,在做对应的任务时,请使用对应的模型
YOLOV11不同任务支持的模型请查看对应官方文档:https://docs.ultralytics.com/models/yolo11/#supported-tasks-and-modes
下载对应任务的模型,使用下面的例子转载对应的模型:
from ultralytics import YOLO
model = YOLO("yolo11m.pt") # 加载目标追踪任务的模型
model = YOLO("yolo11m-seg.pt") # 加载实例分割任务的模型
model = YOLO("yolo11m-pose.pt") # 加载姿态检测任务的模型
model = YOLO("yolo11m-cls.pt") # 加载图像分类任务的模型
model = YOLO("yolo11m-obb.pt") # 加载OBB任务的模型
source = "image.png"
results = model.predict(source)除此之外,如果有自己的自定义模型或者社区模型,也可以直接加载该模型进行推理:
from ultralytics import YOLO
model = YOLO("/path/to/model.pt") # 加载自定义模型
source = "image.png"
results = model.predict(source)模型基本信息
model.model
这是模型的底层网络架构(通常是 PyTorch 模型)。
可以通过
model.model访问模型的详细结构,例如层信息、参数等。
print(model.model)model.names
返回模型的分类类别名称(分类标签)。
是一个字典,键为类别代号,值为类别名称。
print(model.names) # 例如 {0: 'person', 1: 'bicycle', 2: 'car', ...}model.nc
返回模型的分类数量(number of classes)。
print(model.nc) # 例如 80(COCO 数据集)模型配置
model.args
返回模型的推理参数(如置信度阈值、IOU 阈值等)。
是一个字典,包含模型推理时的默认配置。
print(model.args)model.overrides
返回模型加载时的覆盖参数(如果有)。
例如,加载模型时通过
YOLO("yolo11m.pt", task="detect")指定的参数会存储在这里。
print(model.overrides)模型文件信息
model.ckpt
返回模型的检查点路径(即加载的
.pt文件路径)。
print(model.ckpt) # 例如 'yolov8n.pt'model.task
返回模型的任务类型(如
detect、segment、classify等)。
print(model.task) # 例如 'detect'模型性能
model.info()
打印模型的详细信息,包括层数、参数数量、计算量(FLOPs)等。
print(model.info())model.device
返回模型当前所在的设备(如
cpu或cuda:0)。
print(model.device) # 例如 'cuda:0'其他属性
model.model.yaml
返回模型的配置文件内容(YAML 格式)。
包含模型的架构、超参数等信息。
print(model.model.yaml)model.model.stride
返回模型的特征图步长(stride)。
用于计算检测框的尺寸。
print(model.model.stride) # 例如 [8, 16, 32]model.model.weights
返回模型的权重文件路径。
print(model.model.weights)推理
以下会对predict函数进行一系列详细的讲解
资源支持
官方文档: https://docs.ultralytics.com/modes/predict/#inference-sources
使用predict函数时, 它支持的资源不仅仅是图片。YOLO支持推理的资源包括:
✅ 表示该数据源支持在视频或实时流上运行推理(将参数stream设置为True)。
以视频为例:
from ultralytics import YOLO
# 加载预训练的YOLOV11n模型
model = YOLO("yolo11n.pt")
# 定义视频文件的路径
source = "path/to/video.mp4"
# 在源文件上进行推理
# results = model(source, stream=True)
results = model.predict(source, stream=True)predict函数参数
官方文档: https://docs.ultralytics.com/modes/predict/#inference-arguments
predict函数的参数支持如下:
基础参数:
针对可视化(保存的图片等等)的参数:
例子:
from ultralytics import YOLO
# 加载预训练的YOLOV11n模型
model = YOLO("yolo11n.pt")
# 在源文件上进行推理,并指定一些特定的参数
model.predict("bus.jpg", save=True, imgsz=320, conf=0.5)Results对象
官方文档: https://docs.ultralytics.com/modes/predict/#working-with-results
推理完毕后, YOLO会返回一个Results对象, 这个对象包含了推理结果
Results对象具有如下属性:
例子如下:
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
results = model.predict("bus.jpg", save=True, imgsz=320, conf=0.5)
for result in results:
boxes = result.boxes # 保存图像边界框信息的Boxes对象
masks = result.masks # 保存物体遮罩信息的Masks对象
keypoints = result.keypoints # 保存姿态检测信息的Keypoints对象
probs = result.probs # 保存图像分类信息的Probs对象
obb = result.obb # 保存定向边界框信息的Oriented boxes对象
result.show() # 展示推理的结果除了show()方法, result对象也支持如下方法对推理结果进行处理:
Boxes类
在使用目标追踪的模型时,可以调用Boxes类,而Boxes类中还有对应的属性。它们代表了推理的结果
下面是Boxes类的属性:
results = model.predict(img, save=False)
results[0].boxes.cls
results[0].boxes.xywh
results[0].boxes.xyxyn
results[0].boxes.xywhn
results[0].boxes.xyxy训练
train函数
想要训练属于自己的YOLO模型,我们可以使用train函数进行训练,例子如下:
from ultralytics import YOLO, settings
settings.update({
"datasets_dir": BaseProperty.datasets_path,
"weights_dir": BaseProperty.weights_path,
"runs_dir": BaseProperty.output_path,
})
model = YOLO("yolov11m.yaml").load("yolov11m.pt")
results = model.train(data="coco8.yaml", epochs=5, workers=0) # 在windows平台中,workers要设置为0,如果不设置为0,则会报错
print(results)
settings.reset()这里train设置了数据集配置文件coco8.yaml,并且设置了5个epoch
train函数更多的设置如下(官方文档:https://docs.ultralytics.com/modes/train/#train-settings):
模型结构
YOLO在训练前,需要加载模型结构,通常这些模型结构都存放在$python_path$/Lib/site-packages/ultralytics/cfg/models 中,打开YOLOV11的模型结构文件夹(通常带有11或者V11的字样):

这些yaml保存了模型结构,以yolo11.yaml为例:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)配置文件中定义了类别的数量(nc,number of classes)、模型规模(scales)、主干网络(backbone)以及头部网络(head)
模型规模中指定了模型的规模和复杂度(深度、宽度以及最大通道数),每个规模所对应的神经网络隐藏层的数量、参数数量、梯度数量以及GFLOPs值(GFLOPs表示每秒可以执行的十亿次浮点运算,用来评估深度学习模型的计算复杂度。模型的 GFLOPs 值越高,通常意味着模型的计算需求越大,对硬件的要求也越高)可以在注释中看到,这些不同规模的模型在性能和计算复杂度之间提供了不同的平衡
在实际训练加载模型结构时,调用model=yolo11m.yaml就会调用yolo11.yaml 文件中的规模m
Head是模型的头部部分,负责基于Backbone提取的特征图进行具体的任务,如目标检测、分类、回归等。在 YOLO 中,Head 主要负责生成边界框和类别预测。Backbone则是模型的主干部分,负责从输入图像中提取特征。它的主要功能是生成高质量的特征图,这些特征图会被后续的Head部分用于进一步的处理。
from ultralytics import YOLO, settings
settings.update({
"datasets_dir": BaseProperty.datasets_path,
"weights_dir": BaseProperty.weights_path,
"runs_dir": BaseProperty.output_path,
})
# 加载模型
model = YOLO("yolo11m.yaml")
model = YOLO("yolo11m.yaml").load("yolo11m.pt")
# 开始训练
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)加载模型结构时有两种方法,一种是只加载模型结构,就是model = YOLO("yolo11m.yaml") ,这样就可以训练一个全新的模型(注意,从头训练一个复杂的模型需要大量的时间和计算资源)。
另外一种是模型结构后,将现有的预训练的权重加载到模型结构中,就是model = YOLO("yolo11m.yaml").load("yolo11m.pt")。如果想使用自己的模型结构,并且想节省计算资源的情况下得到一个比较好的性能的模型,这个方法是一个不错的选择
预训练模型
预训练模型在深度学习中非常常见,预训练模型通常是在大规模数据集上训练得到的,这些模型已经学到了一些通用的特征表示,可以在许多任务中复用。使用预训练模型可以显著减少训练时间和计算资源,同时提高模型的性能。
我们进入网址(https://docs.ultralytics.com/models/yolo11/#supported-tasks-and-modes)下载的xxxxx.pt,即是官方训练好的预训练模型,里面保存了在ImageNet等大型数据集上面训练好的权重。
微调
微调(Fine-Tuning)通过在预训练模型的基础上进行少量的训练,使其适应新的任务或数据集。微调可以显著提高模型在新任务上的性能,同时减少训练时间和计算资源。
如果不使用微调技术,从零开始训练一个复杂的模型(如 YOLO),通常需要大量的标注数据。具体来说:
目标检测任务:通常需要数千到数万张标注图像。例如,COCO 数据集包含超过 11 万个图像,每个图像平均有 5 个标注对象。
分类任务:对于简单的分类任务,可能需要几百到几千张图像。但对于复杂的多类别分类任务,可能需要数万张图像。
分割任务:分割任务通常需要更多的标注数据,因为每个像素都需要标注。通常需要数千张高质量的标注图像。
使用预训练模型进行微调可以显著减少所需的数据量,因为预训练模型已经在大规模数据集上学习到了丰富的特征表示。具体来说:
目标检测任务:通常需要几百到几千张标注图像。对于一些简单的任务,甚至几十张图像也可能足够。
分类任务:对于简单的分类任务,可能只需要几十到几百张图像。对于复杂的多类别分类任务,可能需要几百到几千张图像。
分割任务:虽然分割任务仍然需要较多的标注数据,但通常几百到几千张图像就足以达到较好的性能。
from ultralytics import YOLO, settings
settings.update({
"datasets_dir": BaseProperty.datasets_path,
"weights_dir": BaseProperty.weights_path,
"runs_dir": BaseProperty.output_path,
})
# 加载模型
model = YOLO("yolo11m.pt")
model = YOLO("/path/to/model.pt")
model = YOLO("yolo11m.yaml").load("yolo11m.pt")
# 开始训练
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)模型微调有几种方式,一种是直接加载预训练模型,即是model = YOLO("yolo11m.pt") ,或者加载自己的模型model = YOLO("/path/to/model.pt") ,后面直接训练,这样就可以达到微调的效果
也可以将现有的预训练的权重加载到模型结构中,后面直接训练即可,这个方法上面有介绍,这里不再阐述
多目标追踪(MOT)
多目标跟踪,一般简称为MOT(Multiple Object Tracking),也有一些文献称作MTT(Multiple Target Tracking)。在事先不知道目标数量的情况下,对视频中的行人、汽车、动物等多个目标进行检测并赋予ID进行轨迹跟踪。不同的目标拥有不同的ID,以便实现后续的轨迹预测、精准查找等工作。
目前实现多目标追踪的算法有:ByteTrack、DeepSort和BoTSort。ultralytics将这些算法(目前为BoTSort和ByteTrack)包装在track函数中
以下是一个例子:
from ultralytics import YOLO
# 加载官方或自定义模型
model = YOLO("yolo11n.pt") # 加载官方目标追踪模型
model = YOLO("yolo11n-seg.pt") # 加载官方目标切割模型
model = YOLO("yolo11n-pose.pt") # 加载官方姿势追踪模型
model = YOLO("path/to/best.pt") # 加载自定义模型
# 开启追踪
results = model.track("https://youtu.be/LNwODJXcvt4", persist=True) # 使用默认追踪算法追踪
results = model.track("https://youtu.be/LNwODJXcvt4", persist=True, show=True, tracker="bytetrack.yaml") # 使用bytetrack进行追踪如果想使用不同的追踪器,在tracker参数中使用如下参数:
BoT-SORT(默认追踪器):
botsort.yamlByteTrack:
bytetrack.yaml
track函数的参数如下:
track函数返回的result与predict基本一致
solutions
YOLO提供了常见场景的现有封装,分别都在ultralytics.solutions的包中,官方文档:Ultralytics Solutions: Harness YOLO11 to Solve Real-World Problems - Ultralytics YOLO Docs
区域目标跟踪
区域目标跟踪通常用于监控特定区域内的目标活动,使用from ultralytics.solutions import TrackZone可以实现对指定区域内目标的检测、跟踪和计数
TrackZone 的主要功能
区域定义:
用户可以定义一个或多个多边形区域(ROI,Region of Interest)。
目标进入、离开或在区域内活动时,会触发相应的事件。
目标跟踪:
结合 YOLO 的目标检测和跟踪功能,实时跟踪目标并分配唯一 ID。
事件触发:
支持自定义事件,例如:
目标进入区域。
目标离开区域。
目标在区域内停留超过指定时间。
计数功能:
统计进入或离开区域的目标数量。
可视化:
在视频帧上绘制区域边界、目标轨迹和事件信息。
以下是一个简单的例子:
import cv2
from common import base_property
from utils import FilePathUtils
from ultralytics.solutions import TrackZone
video_path = FilePathUtils.path_joint_str(base_property.resources_path, "video", "test_person.mp4")
# video = FilePathUtils.path_joint_str(base_property.resources_path, "video", "test_traffic.mp4")
model_path = FilePathUtils.path_joint_str(base_property.resources_path, "weights", "yolo11m.pt")
cap = cv2.VideoCapture(video_path)
region_points = [(150, 150), (1130, 150), (1130, 570), (150, 570)]
tz = TrackZone(
region=region_points,
model=model_path,
persist=True
)
while cap.isOpened():
success, frame = cap.read()
if not success:
break
annotated_frame = tz.trackzone(frame)
cv2.imshow("test_trackzone", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()TrackZone().trackzone(frame)最终会返回一个numpy的array,该array是一个经过处理的视频帧(numpy.ndarray 类型),格式为 (height, width, channels),通常是 BGR 格式(OpenCV 默认格式)。
该帧中会绘制以下内容:
区域边界:定义的跟踪区域(ROI)会被绘制在帧上。
跟踪 ID:每个目标会被赋予一定的ID。
以下是初始化 TrackZone 时的参数:
region表示一个矩形区域,顶点的方向依次为:
左上角
右上角
右下角
左下角
初始化TrackZone时,如果想修改追踪器的参数,只需要调用model.track函数所需的参数即可。