线性表的概念总结
线性表是最基本、最简单、也是最常用的一种数据结构。线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。
线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。注意,这句话只适用大部分线性表,而不是全部。比如,循环链表逻辑层次上也是一种线性表(存储层次上属于链式存储,但是把最后一个数据元素的尾指针指向了首位结点)。
顺序表
采用顺序存储的方式实现线性表简称顺序表,把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现
顺序表的静态实现:采用数组,表初始化后不能扩展存储空间。
顺序表的动态实现:采用动态分配内存,表可任意扩展存储空间
顺序表的优点是随机访问很快,通过数组下标或指针的运算,时间复杂度为O(1),但插入和删除数据的时候,需要移动元素,内存拷贝次数比较多。
总结:
优点:可随机存储,存储密度高。
缺点:要求连续的内存空间,扩容不方便,插入和删除元素需要移动其它的元素。
使用的时候参考数组
c++
int i[] = {1,2,3,4};
cout << i[0] << endl;单链表
单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素+指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
单链表设置头结点的作用是:为保证处理第一个结点和后面结点的算法相同,使程序更高效

优点:不要求连续的内存空间,扩容很方便,插入和删除元素不需要移动其它的元素。
缺点:不支持随机访问,指针需要消耗空间。只能由开始结点走到终端结点。因此访问效率低

//q->next = p,在qp之间插入结点s
q->next = s;s->next = p;
//q->next = s,s->next = p在qp之间删除结点s
q->next = p;free(s);双链表
以下图片原链接:双向链表及其创建(C语言)详解 (biancheng.net)
双链表就是在单链表结点上增添了一个指针域,指向当前节点的前驱。对于逆向查找(从后往前)相关的问题,使用双链表,会更加事半功倍。
与单链表相比,双链表的优点之一为:访问前后结点更灵活

优点:从双链表中的任意一个结点开始,都可以很方便地访问前驱结点和后继结点。
缺点:增加删除节点复杂,需要多分配一个指针存储空间。
//q->next = p,p->prior = q,在qp之间插入结点s
q->next = s;s->next = p;s->prior = q;s->next = p;
//q->next = s,s->next = p,s->prior = q;s->next = p在qp之间删除结点s
q->next = p;p->prior = q;free(s);循环单链表
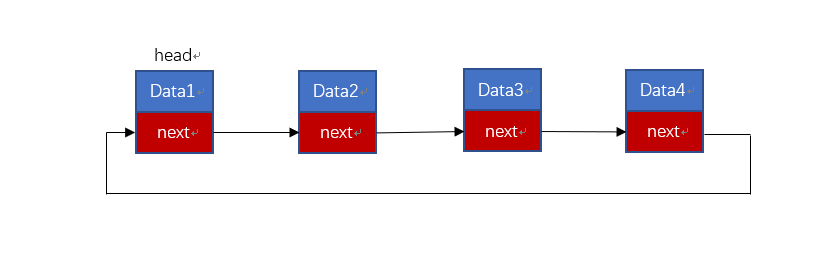
将当链表的最后一个指针域指向链表中的第一个结点即可。若第一个结点为头结点,则最后一个结点连接的是头结点,若单链表没有头结点,则最后一个指针域要指向开始结点。
循环单链表的最大优点是:从任何一个结点出发都能够访问到链表中的其他所有的结点