
python爬虫大总结
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
Requests和Beautifulsoup4组合
requests:其库中的 get() 方法能向服务器发送了一个请求,请求类型为 HTTP 协议的 GET 方式;post() 方法,也能向服务器发送一个请求,请求类型是 HTTP 协议的 POST 方式,可根据访问的网页而定。
beautifulsoup4:Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
安装
pip install requests (python3自带)
pip install beautifulsoup4导入
import requests; # requests
from bs4 import BeautifulSoup; # beautifulsoup4request
Python的request库用于发送HTTP请求,使用该库可以执行各种HTTP操作,例如获取WEB页面、发送PST和GET请求、上传文件、处理Cookie和Session请求等等。以下是用request请求的案例:
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')请求的含义如下:
GET: 请求指定的页面信息,并返回实体主体。
POST: 请求服务器接受所指定的文档作为对所标识的URI的新的从属实体。
PUT: 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE: 请求服务器删除指定的页面。
HEAD: 只请求页面的首部。
get 和 post比较常见 GET请求将提交的数据放置在HTTP请求协议头中;POST提交的数据则放在实体数据中
Get
使用get请求的案例如下:
# 导入 requests 包
params_map = {'keyword': 'hello world'}
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76'} # 请求头
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
response = requests.get("https://www.baidu.com/", params=params_map, headers=headers)
# 查看响应状态码
print(response.status_code)
# 查看响应头部字符编码
print(response.encoding)
# 查看完整url地址
print(response.url)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print(response.text)每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息。具体的响应信息如下:
属性或方法 | 说明 |
|---|---|
apparent_encoding | 编码方式 |
close() | 关闭与服务器的连接 |
content | 返回响应的内容,以字节为单位 |
cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
encoding | 解码 r.text 的编码方式,可以对encoding进行设置,比如re.encoding = "UTF-8" |
headers | 返回响应头,字典格式 |
history | 返回包含请求历史的响应对象列表(url) |
is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
iter_content() | 迭代响应 |
iter_lines() | 迭代响应的行 |
json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
links | 返回响应的解析头链接 |
next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
ok | 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
reason | 响应状态的描述,比如 "Not Found" 或 "OK" |
request | 返回请求此响应的请求对象 |
status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
text | 返回响应的内容,unicode 类型数据 |
url | 返回响应的 URL |
Post
使用post请求的案例如下:
# 表单参数,参数名为 name 和 age
request_data = {'name': 'john', 'age': '12'}
# 发送请求
response = requests.post('https://www.form.com/demo.php', data=request_data)
# 返回网页内容
print(response.text)beautifulsoup4
BeautifulSoup4是Python中一个用于解析HTML和XML文档的第三方库。它提供了一种简单而直观的方式来遍历文档、搜索特定元素以及对文档进行修改等操作。
使用BeautifulSoup4,你可以很方便地获取文档中的各种标签和属性,通过这些标签和属性,你可以提取出文本、图片、链接等内容。此外,它还支持CSS选择器和正则表达式等方式来查找和处理文档中的元素。
创建beautifulsoup对象
为了使用beautifulsoup,我们需要创建一个beautifulsoup对象:
soup = BeautifulSoup(html_doc, 'html.parser')html_doc为要解析的HTML或XML文档。通常为request返回的response中的html文档,所以我们可以这样:
response = requests.get("https://www.baidu.com/")
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')我们也可以对本地html文件进行解析
with open("index.html") as f:
html = f.read()
soup = BeautifulSoup(response.text, 'html.parser')
soup = BeautifulSoup(open("index.html"))在进行解析后,可以让beatifulsoup进行格式化输出:
print(soup.prettify()) # prettify()负责将文档格式化输出,方便查看。搜索元素(文档树)
对html解析后,我们可以使用find_x方法查找HTML文档树(层级结构),常用方法如下:
soup.find() # 查找符合条件的第一个元素
soup.find_all() # 查找所有符合条件的元素
soup.find_parent() # 查找当前元素的父元素,返回Tag对象。
soup.find_parents() # 查找当前元素的所有祖先元素,返回Tag对象的生成器。
soup.find_next_sibling() # 查找当前元素的下一个兄弟元素,返回Tag对象。
soup.find_next_siblings() # 查找当前元素的所有后续兄弟元素,返回Tag对象的生成器。
soup.find_previous_sibling() # 查找当前元素的上一个兄弟元素,返回Tag对象。
soup.find_previous_siblings() # 查找当前元素的所有前面的兄弟元素,返回Tag对象的生成器。
soup.find_next() # 查找当前元素的下一个元素,返回Tag对象。
soup.find_all_next() # 查找当前元素后面的所有元素,返回Tag对象的生成器。
soup.find_previous() # 查找当前元素的上一个元素,返回Tag对象。
soup.find_all_previous() # 查找当前元素前面的所有元素,返回Tag对象的生成器。其中,find()和find_all()比较常用
find()的语法为:
soup.find(name=None, attrs={}, recursive=True, text=None, **kwargs)形参解释如下:
name: 要查找的标签名,如'div'、'a'等attrs: 要查找的属性名和属性值,可以是一个字典、一个关键字参数或一个正则表达式,如{'class': 'myclass', 'data-type': 'text'}、id='myid'、href=re.compile('^https://')等recursive: 是否递归查找子节点,默认为Truetext: 要查找的文本内容,如'hello world'等**kwargs: 要查找的其他属性名和属性值,如data-type='text'等。
如果找到符合条件的元素,返回该元素的Tag对象;否则返回None。
find_all()的语法为:
soup.find_all(name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)其中,name、attrs、recursive、text、**kwargs的含义与find()方法相同,limit为限制返回的结果数量,默认为None,表示返回所有符合条件的元素。
如果找到符合条件的元素,返回一个列表,其中包含所有符合条件的元素的Tag对象;否则返回一个空列表[]。
例如,假设有如下HTML文档:
<!DOCTYPE html>
<html>
<head>
<title>Example</title>
</head>
<body>
<div id="content">
<h1 class="title">Hello World</h1>
<p class="text">This is an example.</p>
</div>
</body>
</html>我们可以使用find()方法查找第一个<div>标签,find_all方法查找所有<div>标签,代码如下:
html_doc = """
<!DOCTYPE html>
<html>
<head>
<title>Example</title>
</head>
<body>
<div id="content">
<h1 class="title">Hello World</h1>
<p class="text">This is an example.</p>
</div>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
div_tag = soup.find('div') # 查找第一个<div>标签
div_tags = soup.find_all('div') # 查找所有<div>标签
print(div_tag)
print(div_tags)其余函数与find()和find_all()无异,不再赘述
层级遍历文档树
通常HTML文档存在多级标签,我们可以通过调用tag.children的方法遍历该标签的子层标签,例如,考虑以下HTML文档:
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<div class="content">
<h1 class="title">Hello World</h1>
<p class="text">This is an example.</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
</div>
</body>
</html>要提取这个文档中的信息,我们需要一层层地进入标签的嵌套层次。例如,要提取<div>标签下的所有子元素,可以使用以下代码:
soup = BeautifulSoup(html_doc, 'html.parser')
div_tag = soup.find('div', {'class': 'content'})
for child in div_tag.children:
print(child)运行结果为:
<h1 class="title">Hello World</h1>
<p class="text">This is an example.</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>类似地,我们可以使用descendants属性来获取<div>标签的所有后代元素,包括它的子元素、孙子元素以及更深层次的元素。例如,要获取<div>标签的所有后代元素,可以使用以下代码:
soup = BeautifulSoup(html_doc, 'html.parser')
div_tag = soup.find('div', {'class': 'content'})
for descendant in div_tag.descendants:
print(descendant)运行结果为:
<h1 class="title">Hello World</h1>
Hello World
<p class="text">This is an example.</p>
This is an example.
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
<li>Item 1</li>
Item 1
<li>Item 2</li>
Item 2
<li>Item 3</li>
Item 3层级搜索文档树
在BeautifulSoup中,我们可以使用层级搜索来搜索特定的文档树。即使用find().find()这样的套娃方式去搜索,例如,假设我们有以下HTML文档:
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<div class="content">
<h1 class="title">Hello World</h1>
<p class="text">This is an example.</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
</div>
<div class="sidebar">
<h2 class="subtitle">Recent Posts</h2>
<ul>
<li><a href="#">Post 1</a></li>
<li><a href="#">Post 2</a></li>
<li><a href="#">Post 3</a></li>
</ul>
</div>
</body>
</html>我们可以使用以下代码来搜索<div>标签的子元素中的所有<li>标签:
soup = BeautifulSoup(html_doc, 'html.parser')
div_tag = soup.find('div', {'class': 'content'})
li_tags = div_tag.find_all('li')
for li_tag in li_tags:
print(li_tag.text)运行结果为:
Item 1
Item 2
Item 3可以看到,在进行find()搜索<div>标签后,又再一次进行find_all()搜索了标签,这样的嵌套是返回了Tag对象后才能进行的
四大对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,上面提到的Tag对象就是对象的其中一种,所有对象可以归纳为4种:
Tag
NavigableString
BeautifulSoup
Comment
Tag
Tag对象对应为HTML中的标签,例如:
<h1 class="title">Hello World</h1>除了find函数,beatifulsoup同样提供了方便直接的办法去获取通用的Tag,比如说:
print(soup.title) # 获取title标签
print(soup.head) # 获取head标签
print(soup.a) # 获取a标签
print(soup.p) # 获取p标签tag有两个重要的属性,name 和 attrs:
print(soup.name)
print(soup.a.name)
print(soup.attrs)
print(soup.p.attrs) # 把p标签的所有属性打印输出了出来,得到的类型是一个字典。
print(soup.p['class']) # 单独获取某个属性
print(soup.p.get('class')) # 单独获取某个属性,与p['class']作用一致可以对这些属性和内容等等进行修改:
soup.p['class']="newClass"也可以删除这些属性
del soup.p['class']NavigableString
得到了标签的内容后,可以用.string获取标签内部的文字,例如:
print(soup.p.string)它的类型是一个NavigableString,叫可导航字符串。它可以获取tag标签内部的文字,比如<h1 class="title">Hello World</h1>中的Hello World
BeautifulSoup
BeautifulSoup对象表示的是一个文档的全部内容。大部分时候,可以把它当作Tag对象,是一个特殊的Tag,我们可以分别获取它的类型,名称:
print(type(soup.name))
#<type 'unicode'>
print(soup.name)
# [document]
print(soup.attrs)
#{} 空字典Comment
在HTML文档中,有时会添加注释信息,这些注释信息在网页上是不显示的,但可以通过BeautifulSoup来提取和处理。
BeautifulSoup提供了Comment类来处理HTML文档中的注释。我们可以使用soup.comments来查找文档中的注释信息。
例如,考虑以下HTML文档:
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
<!-- This is a comment -->
</body>
</html>可以使用以下代码来提取注释信息:
from bs4 import BeautifulSoup, Comment
soup = BeautifulSoup(html_doc, 'html.parser')
comments = soup.comments
for comment in comments:
print(comment)运行结果为:
This is a comment 注意,BeautifulSoup将注释信息看作是一个独立的节点,所以可以通过节点操作来处理注释信息。例如,可以使用soup.find_all(text=lambda text: isinstance(text, Comment))来查找文档中的注释信息。
Scrapy
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
scrapy基本结构
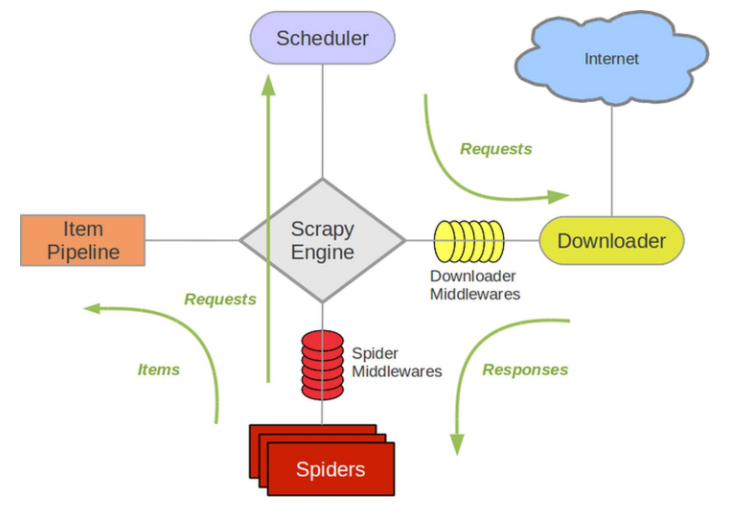
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline) 、Scrapy引擎(Scrapy Engine)。
调度器(Scheduler):
把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
下载器(Downloader):
它是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是** Scrapy下载器是建立在twisted这个高效的异步模型上的**(其实整个框架都在建立在这个模型上的)。
爬虫(Spider):
它是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息 ,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。类似于springboot中的controller。
实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息 。类似于java中的orm,是操作数据库的。Item类似于java中的实体对象,Pipeline更像数据库中的业务操作。
Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
整体架构图
xpath
符号 | 说明 |
|---|---|
/ | 从根节点选取,使用绝对路径,路径必须完全匹配 |
// | 从整个文档中选取,使用相对路径 |
. | 从当前节点开始选取 |
… | 从当前节点父节点开始选取 |
@ | 选取属性 |
text() | 获取文本 |
案例
路径表达式 | 结果 |
|---|---|
body | 选取 body 元素的所有子节点。 |
/head | 选取根元素下head。假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
div/a | 选取属于 div 的子元素的所有 a 元素。 |
//a | 选取所有 a 子元素,而不管它们在文档中的位置。 |
div//a | 选择属于 div 元素的后代的所有 a 元素,而不管它们位于 bookstore 之下的什么位置。 |
//@class | 选取名为 class 的所有属性。 |
./a | 选取当前元素下的a |
…/a | 选取父元素下的a |
a/@href | 选取a标签的href属性 |
a/text() | 选取a标签下的文本 |
安装
pip install scrapy常用命令
创建scrapy项目
scrapy startproject baidu(项目名)目录大致如下:
目录的解释为:
scrapy.cfg:项目的配置文件
baidu/:该项目的python模块。之后在这个地方加代码
baidu/items.py:项目中的item文件
baidu/pipelines.py:项目中的pipelines文件
baidu/settings.py:项目中的设置文件
baidu/spiders/:放置spider代码的目录
生成爬虫
cd baidu/spiders/(项目名/spiders/)
scrapy genspider baidu(爬虫名) www.baidu.com(域名)启动爬虫
cd baidu(scrapy.cfg的项目所在地)
scrapy crawl baidu(爬虫名)制作 Scrapy 爬虫的步骤
新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
超简单入门小案例
以下案例为介绍最简单的流程
新建项目
scrapy startproject mySpider明确目标,编写items.py
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()制作爬虫
首先新建爬虫文件
cd ./mySpider/spiders
scrapy genspider itcast "itcast.cn"打开 mySpider/spider目录里的 itcast.py,修改start_urls属性以及parse()方法
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ["http://www.itcast.cn/channel/teacher.shtml"] # 要爬的url
def parse(self, response):
# 获取网站标题
context = response.xpath('/html/head/title/text()')
# 提取网站标题
title = context.get()
print(title)运行爬虫
命令行模式:
cd mySpider
scrapy crawl itcast脚本模式:
新建mian.py,加入如下代码
from scrapy import cmdline
cmdline.execute("scrapy crawl itcast".split())运行代码即可
获取资源
四个方法:get() 、getall() 、extract() 、extract_first()
get() :获取头一个数据,没有的时候返回None
getall() :获取所有的数据,没有的时候返回None
extract() :获取所有的数据,没有的时候抛出一个错误
extract_first():获取头一个数据,没有的时候抛出一个错误
get() 、getall() 是新版本的方法,extract() 、extract_first()是旧版本的方法。
titleXPATH = response.xpath('//*[@class="card-item"]/h3/a/text()') # 通过text()寻找文字
titles = titleXPATH.getall() # 获取所有的信息,返回一个list
titles = titleXPATH.get() # 获取一个信息,返回一个str
titles = titleXPATH.extract() # 获取所有的信息,返回一个list
titles = titleXPATH.extract_first() # 获取一个信息,返回一个str抓取新连接
有时在旧的连接中有新的连接,这个时候就需要抓取新的连接的内容,关键代码如下:
yield scrapy.Request(url=next_url, dont_filter=True, callback=self.next)参数如下:
url:下一个要抓的url
dont_filter:关闭默认过滤掉重复的请求URL的功能
callback:调用的方法
Demo:
class YgoSpider(scrapy.Spider):
name = 'ygo'
allowed_domains = ['ygo']
start_urls = ['http://www.ourocg.cn/card/list-1/1']
def parse(self, response):
self.next(response) # 第一次抓取的直接调用
i = 2
while (i < 10):
next_url = "http://www.ourocg.cn/card/list-1/" + str(i) # 获取每一页的url
yield scrapy.Request(url=next_url, dont_filter=True, callback=self.next) # 继续爬
i += 1
def next(self, response):
titleXPATH = response.xpath('//*[@class="card-item"]/h3/a/text()') # 通过text()寻找文字
titles = titleXPATH.getall() # 获取所有的信息,返回一个list
print(titles)